Posted on February 12, 2019
By Shawn Douglas
Journal articles
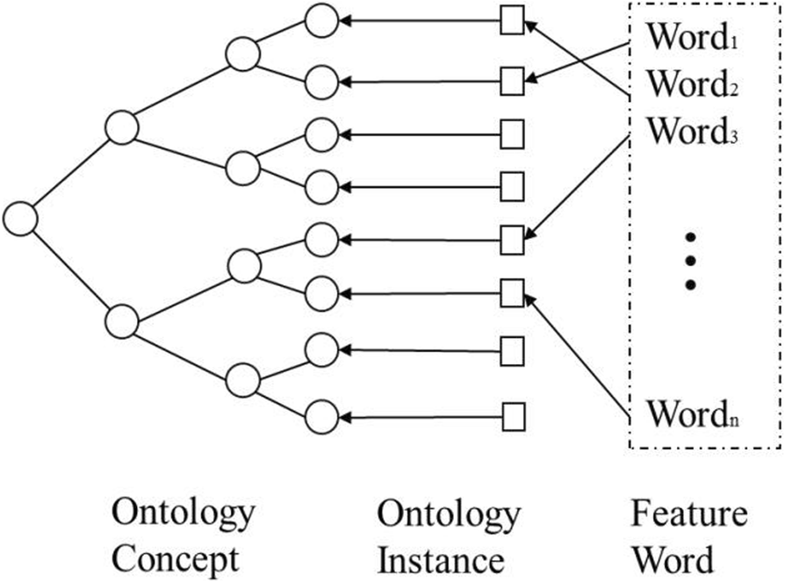
Whether it's a document management system or a laboratory information management system, some sort of query function is involved to help the user find specific documents or data. How that data is retrieved—using information retrieval methods—can vary, however. In this 2019 paper published in
EURASIP Journal on Wireless Communications and Networking, Binbin Yu details a modified information retrieval methodology that uses a domain-ontology-based approach that integrates document processing and retrieval aspects of the query. Domain ontology takes into account semantic information and keywords, which improves recall and precision of results. After explaining the mathematics and experimentation methodology, Yu concludes "the genetic algorithm shortens the distance compared with simulated annealing, and the ontology retrieval model exhibits a better precision and recall rate to understand the users’ requirements."
Posted on February 5, 2019
By Shawn Douglas
Journal articles
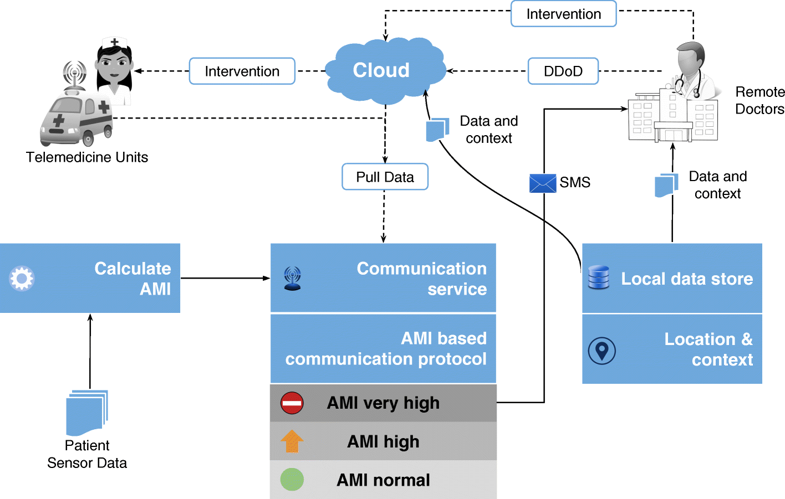
In this late 2018 paper published in
BMC Medical Informatics and Decision Making, Pathinarupothi
et al. with the Amrita Institute of Medical Sciences present their Rapid Active Summarization for Effective Prognosis (RASPRO) framework for healthcare facilities. Noting an increasing volume of data coming from body-attached senors and a lack of making the best sense of it, the researchers developed RASPRO to provide summarized patient/disease-specific trends via body sensor data and aid physicians in being proactive in more rapidly identifying the onset of critical conditions. This is done through the implementation of "physician assist filters" or PAFs, which also enable succinctness and decision making even over bandwidth-limited communication networks. They conclude the system "helps in personalized, precision, and preventive diagnosis of the patients" while also providing the benefits of availability, accessibility, and affordability for healthcare systems.
Posted on January 28, 2019
By Shawn Douglas
Journal articles
What do you do when your newborn screening program grows in importance, beyond its original data management origins in a time of cloud computing and integrated informatics systems for healthcare? Entities such as Newborn Screening Ontario (NSO) have risen to the challenges inherent to this question, undertaking an end-to-end assessment of their needs and existing capabilities, in the process deciding on "a holistic full product lifecycle redesign approach." This paper describes the full process as conducted by NSO, from theory to practice. The authors conclude "that developing, implementing, and deploying a [screening information management system] is about much more than the technology; team engagement, strong leadership, and clear vision and strategy can lead newborn screening programs looking to do the same to success and long-term gains in patient outcomes.
Posted on January 21, 2019
By Shawn Douglas
Journal articles
In this 2019 paper written by New York University School of Medicine's Kevin B. Read, the topic of clinical research data management (CRDM) is discussed, particularly in its application at the NYU Health Sciences Library. Identifying a strong need by the clinical research community at the university for CRDM training, Read—acting as the Data Services Librarian and Data Discovery Lead—developed curriculum to support such a mission and offered training. This article details his journey as such, ending with supporting data and a strong feeling that the end result is a "research community being better trained, more compliant, and increasingly aware of established institutional workflows for clinical research."
Posted on January 14, 2019
By Shawn Douglas
Journal articles
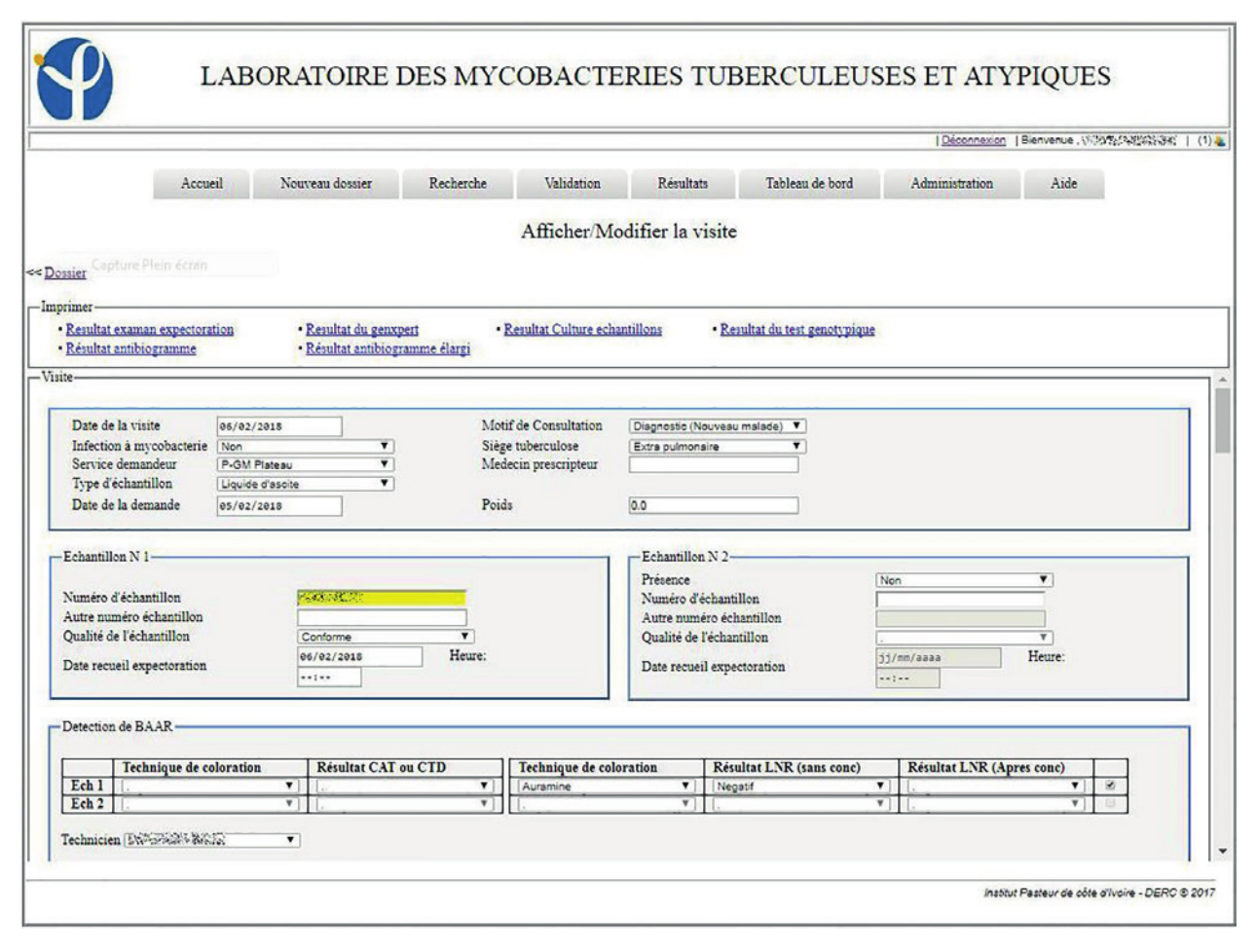
In this 2019 paper, Koné
et al. of the Pasteur Institute of Côte d’Ivoire provide insight into their self-developed laboratory information system (LIS) specifically designed to meet the needs of clinicians treating patients infected with
Mycobacterium tuberculosis. After discussing its design, architecture, installation, training sessions, and assessment, the group describes system launch and how its laboratorians perceived the change from paper to digital. With some discussion, they conclude they have improved, more real-time "indicators on the follow-up of samples, the activity carried out in the laboratory, and the state of resistance to antituberculosis treatments" with the conversion.
Posted on January 7, 2019
By Shawn Douglas
Journal articles
Attempting to implement a regional public health initiative affecting thousands of children is daunting enough, but collecting, analyzing, and reporting critical data that shows efficacy can be even more challenging. This 2018 article published in
Public Health Research & Practice demonstrates one approach to such an endeavor in New South Wales Australia. Green
et al. discuss the design and implementation of their Population Health Information Management System (PHIMS) to integrate and act upon data associated with not one but two related public health programs targeting the prevention of childhood obesity. The article also discusses some of the challenges with the project, from funding and training all 15 New South Wales local health districts to ensuring support across all the districts for consistent operation and security despite differing IT infrastructures. They conclude that despite the challenges, their award-winning PHIMS solution has been vital to the two programs' success.
Posted on December 18, 2018
By Shawn Douglas
Journal articles
In this brief paper published in
Folia Forestalia Polonica, Series A – Forestry, Dorota Grygoruk of Poland's Forest Research Institute presents the development of the open data concept within the context of Poland and other countries, while also addressing how data sharing and management is challenged by the paradigm. Grygoruk first defines the open data and open access concepts and then describes how policy in Poland and the European Union has been adopted to specify those concepts within institutions. The author then analyzes the challenges of implementing data sharing inherent to research data management, including within the context of forestry informatics. The conclusion? The "organizational and technological solutions that enable analysis" are increasingly vital, and " it becomes necessary for research institutions to implement data management policies," including data sharing policies.
Posted on December 11, 2018
By Shawn Douglas
Journal articles
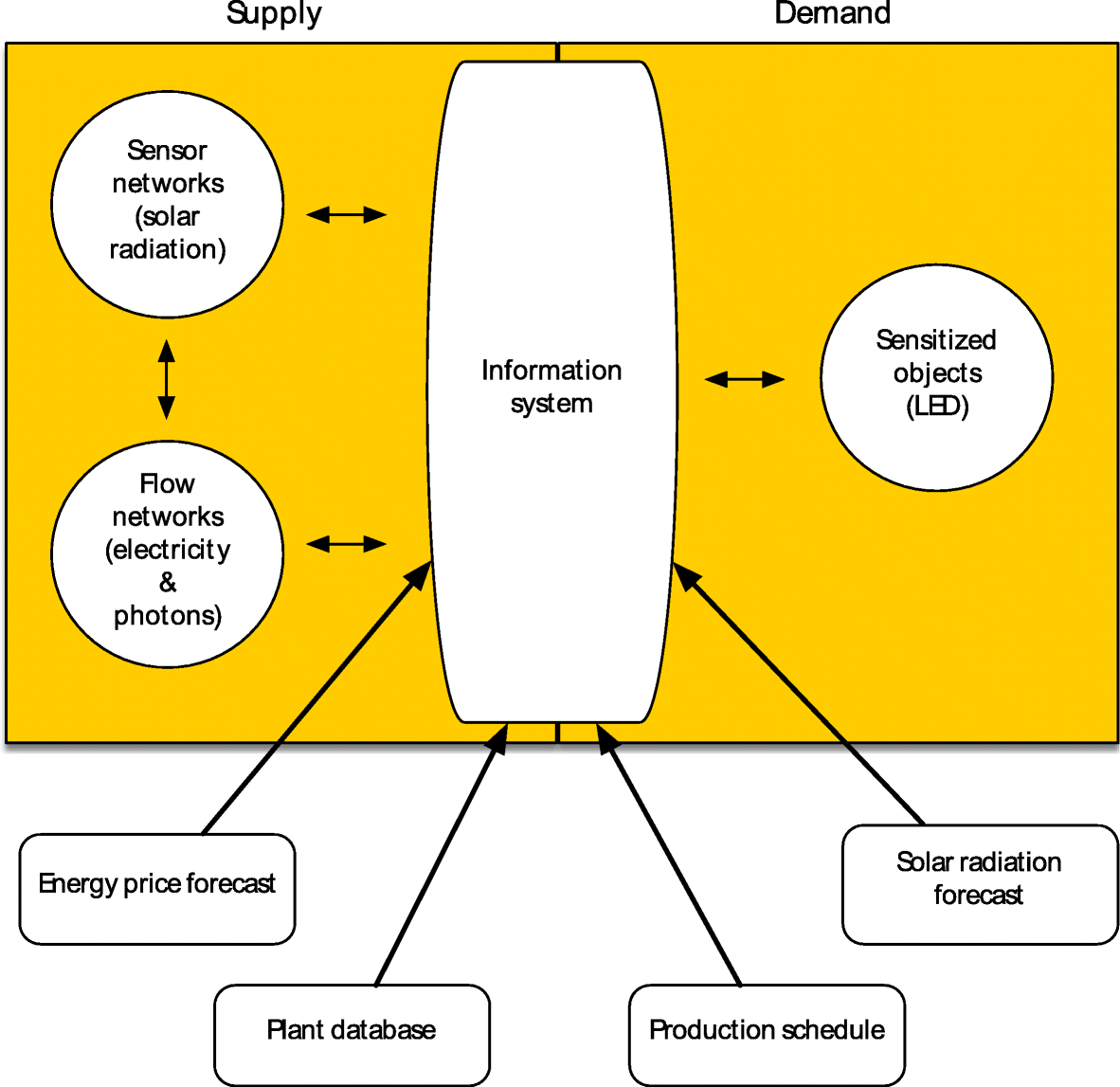
In the inaugural issue of the journal
Energy Informatics, Watson
et al. of the University of Georgia - Athens provide research and insight into how databases, data streams, and schedulers can be joined with an information system to drive more cost-effective energy production for greenhouses. Combining past research and new technologies, the authors turn their sights to food security and the importance of developing more efficient systems for greater sustainability. They conclude that an energy informatics framework applied to controlled-environment agriculture can significantly reduce energy usage for lighting, though "engaging growers will be critical to adoption of information-systems-augmented adaptive lighting."
Posted on December 4, 2018
By Shawn Douglas
Journal articles
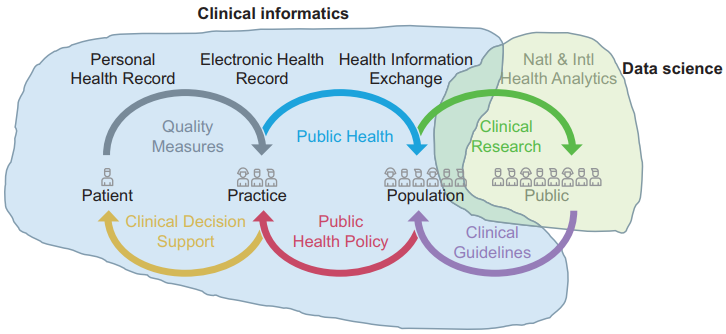
In this brief collaborative article by various researchers in the United Kingdom, a statement of fact is quickly set out for the reader: health data science and clinical informatics have a considerable gap between each other that must be addressed. Wasting no time, Scott
et al. dig into the U.K. context of "the operational realities of health data quality and the implications for data science." Collected clinical data is "problematic," they claim, and clinical informaticians don't always link the "two cultures" of using 1. clinical data and knowledge as a primary tool to 2. improve human health outcomes. They close by recognizing existing efforts to bridge the gap between the two cultures and make recommendations of their own such as recognizing "the interdisciplinary nature of biomedical informatics" and a need for "a significant expansion of clinical informatics capacity and capability."
Posted on November 26, 2018
By Shawn Douglas
Journal articles
Kristin Briney, Data Services Librarian at the University of Wisconsin - Milwaukee, gives a brief commentary on the perils of managing research data with inconsistent or non-standardized date formats. Tapping into the stories of statisticians and ecologists, Briney notes that despite being a more western, Gregorian-based system, the international standard ISO 8601 provides benefits of consistency, formatting, extensibility, and sorting. And while ISO 8601 doesn't play nicely with Microsoft Excel, the author provides several ways around the problem. She concludes that "ISO 8601 is a natural partner for research data management" and encourages other researchers to adopt the standard.
Posted on November 20, 2018
By Shawn Douglas
Journal articles

What can medical librarians do to better support patrons? How can clinical medicine and research librarians work together to foster an environment of improved research cycles and patient outcomes? Bardyn
et al. address these concerns and others through a demonstration of what the University of Washington's Translational Research and Information Lab (TRAIL) program has accomplished since its inception. The authors introduce basic concepts in clinical and translational research and then provide background and methodology for how they improved researcher-focused spaces, clinical research support services, and research data management services. They conclude that "initiatives like TRAIL are vital to supporting universities’ clinical data research efforts," noting that "[i]n uniting leading on-campus health sciences organizations, such initiatives build off the strengths of each partner" and encourage new skill sets to be developed to support cross-discipline research on campus.
Posted on November 12, 2018
By Shawn Douglas
Journal articles
So much data is being collected from healthcare recipients, online banking users, online shoppers, and more, and what's worse is we're often letting companies do it without reading the terms of use, according to Rao
et al. in this 2018 paper. So what can be done to better preserve our data privacy? The authors first look at four major threats to our data privacy (surveillance, disclosure, discrimination, and personal embracement and abuse), then delve into seven different techniques for preserving the privacy of our data. Giving their pros and cons, the authors finally propose a hybrid solution revolving around the concept of the "data lake" and privacy preserving algorithms.
Posted on November 6, 2018
By Shawn Douglas
Journal articles
This brief article published in
Journal of Taibah University Medical Sciences in 2017 looks at public health informatics (PHI) from the perspective of a researcher in the Kingdom of Saudi Arabia. Aziz discusses the concept of PHI and then looks at the various surveillance systems within PHI. Later he delves into the challenges provided by paper-based systems and how electronic systems can alleviate them. He closes with a discussion of PHI in the Kingdom of Saudi Arabia and concludes that various "applications and initiatives are currently available to meet the growing needs for faster and accurate data collection methods" in the country, as well as around the world.
Posted on November 1, 2018
By Shawn Douglas
Journal articles
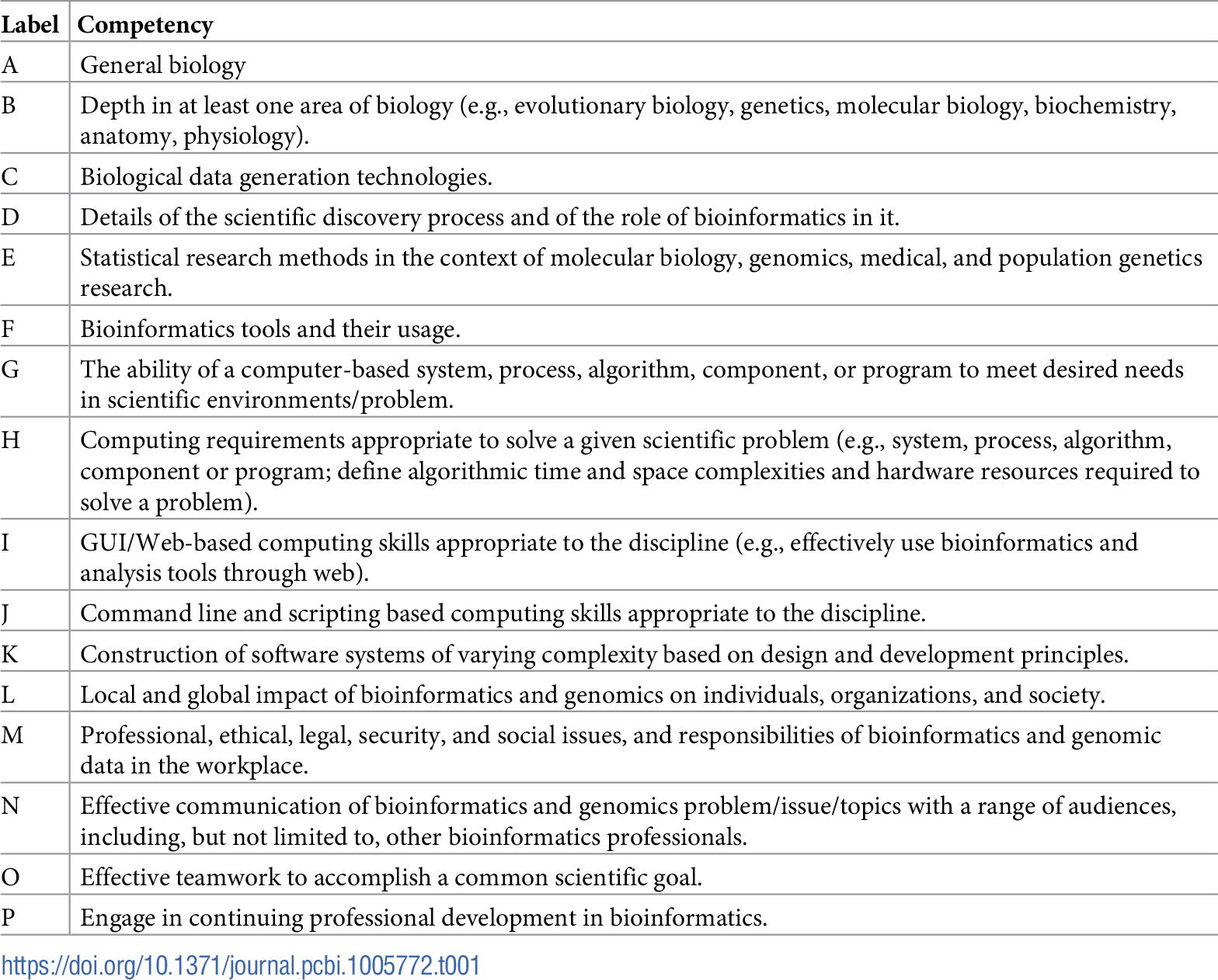
In this 2018 article by Mulder
et al., a broad collective of knowledge and experience is brought together to better shape the competencies required for a modern bioinformatics education program and their training contexts. Need is immense, yet methodologies are diverse, necessitating cooperation to refine core competencies for different groups. The authors describe the development of these competencies and then provide practical use cases for them. They conclude the competencies "provide a basis for the community of bioinformatics educators, despite widely divergent goals and student populations, to draw upon their common experiences in designing, refining, and evaluating their own training programs." However, they also caution that they shouldn't be viewed as "a prescription for a specific set of curricula or curricular standards."
Posted on October 23, 2018
By Shawn Douglas
Journal articles
This paper by Malykh and Rudetskiy "discusses different approaches to building a clinical decision support system based on big data," with a focus on non-biased processing methods and their comparative assessments. After an in-depth analysis of methods and objectives, the authors present their findings from the clinical decision support data and their significance. They conclude that case-based and precedent-based approaches each have their advantages--including more accurate recommendations and faster system speeds--but are not without disadvantages. The authors suggest future research is needed to address "problems with optimization of provided metrics, compression of state descriptions, and construction of training procedures."
Posted on October 14, 2018
By Shawn Douglas
Journal articles
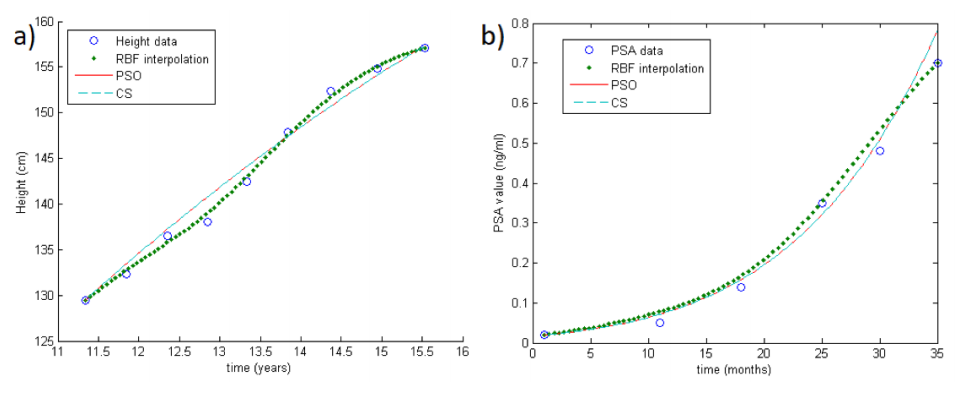
When it comes to longitudinal data, what analysis methods are we using today? How can they be applied to clinical data? In this 2018 paper, Stura
et al. look at, for example, repeated data from measuring patient reactions and behaviors to a therapy. yet when analyzing this type of data problems arise; "more robust statistical methods" are required. The authors combine several methods to develop a "numerical tool based on optimization methods coupled with interpolation techniques." They conclude that it provides several benefits, including output displayed as "a (continuous) growth curve, allowing the analysis of each growth function independently of the others. "
Posted on October 7, 2018
By Shawn Douglas
Journal articles

In this 2018 paper, El aboudi and Benhilma discuss the data management architectures of healthcare from the perspective of Northern Africa. As part of their discussion, the authors propose "an extensible big data architecture based on both stream computing and batch computing in order to enhance further the reliability of healthcare systems by generating real-time alerts and making accurate predictions on patient health condition." With such an architecture, they conclude that, when implemented well, the healthcare system may be "capable of handling the high amount of data generated by different medical sources in real time."
Posted on October 2, 2018
By Shawn Douglas
Journal articles
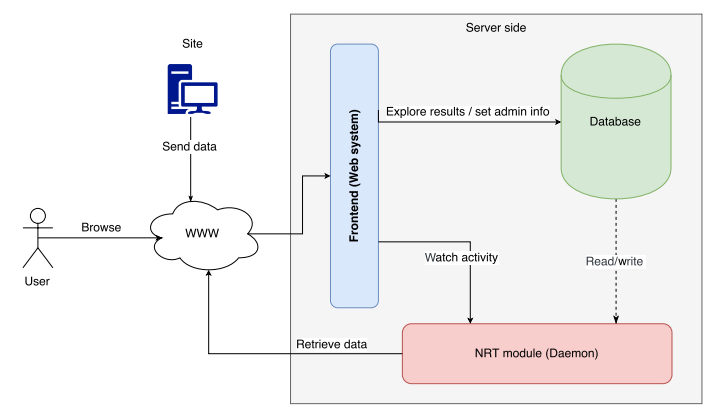
In this 2018 paper published in
Geoscientific Instrumentation, Methods and Data Systems, Fuertes
et al. describe and demonstrate the uses of CÆLIS, software designed to simplify the processing, management, and use of atmospheric particulate data. After describing the architecture and database model, the authors describe its functionality and real-world applications. The authors conclude that the automation the software brought to aerosol measurement and analysis has been significant, in that software "has reduced the number of human errors and allowed one to perform more in-depth and exhaustive analysis" while also allowing users to "perform queries and extract data in a fast and very flexible way."
Posted on September 24, 2018
By Shawn Douglas
Journal articles
In this 2018 paper published in
Research Ideas and Outcomes, Borghi
et al. of the University of California Curation Center discuss their suite of research data management (RDM) tools, Support Your Data. The tools "include a rubric designed to enable researchers to self-assess their current data management practices and a series of short guides which provide actionable information about how to advance practices as necessary or desired." Based on three key RDM trends, the researchers felt a need to provide a complementary set of tools for researchers to better address those trends. The conclude by offering several use cases for the tools and planning "next steps" for improving the tools.
Posted on September 18, 2018
By Shawn Douglas
Journal articles

Baseman
et al. "conducted an assessment of big data that is available to a [public health agency]—laboratory test results and clinician-generated notifiable condition report data—through its participation in a [health information exchange]" and published their results in
Informatics. They identified five major challenges to "secondary use of HIE data for meeting public health communicable disease surveillance needs" and then find ways to turn those challenges into opportunities for the public health system, ultimately optimizing it through various forms of big data analysis and management.






