Posted on September 11, 2018
By Shawn Douglas
Journal articles
This brief article published in
Frontiers in Public Health takes a look at the collective management of genetic analysis techniques and "the ethico-legal frameworks" associated with forensic science and biomedicine. Krikorian and Vailly introduce the ethics and data collection methods of genetic material by police, noting how with new techniques the ethics have changed. Then they discuss the legal and political ramifications that go along with the ethics. They conclude that questions persist "about the conditions for the existence or for the absence of political controversies that call for further sociological investigations about the framing of the issue and the social and political logic at play." Additionally, they note "the need for promoting dialogue among the various professionals using this technology in police work" as well as "with healthcare professionals."
Posted on September 4, 2018
By Shawn Douglas
Journal articles
In this 2018 paper by Irawan and Rachmi, a proposed research data management plan (RDMP) for the university ecosystem is proposed. After introducing the concept of an RDMP and the layout, the authors describe seven major components to their plan, in the form of an assessment form: data collection; documentation and metadata; storage and backup; preservation; sharing and re-use; responsibilities and resources; and ethics and legal compliance. They conclude that the assessment form can help researchers "to describe the setting of their research and data management requirements from a potential funder ... [and] also develop a more detailed RDMP to cater to a specific project's environment."
Posted on August 27, 2018
By Shawn Douglas
Journal articles
In this 2016 paper published in
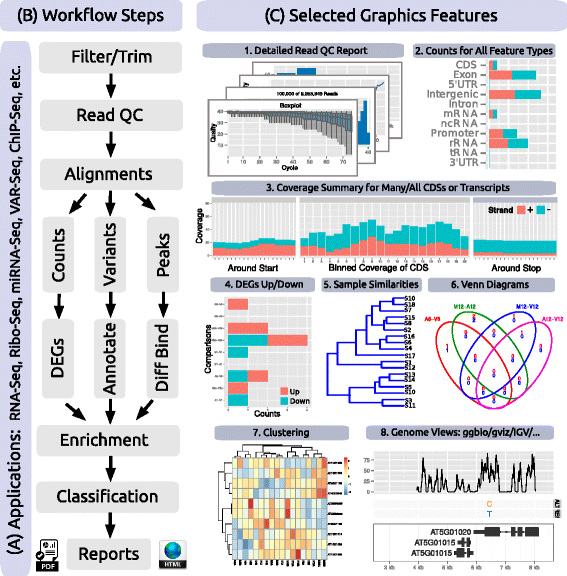
BMC Bioinformatics, Backman and Girke discuss the R/Bioconductor package systemPipeR. Recognizing that the analysis of next-generation sequencing (NGS) data remains a significant challange, the authors turned to the R programming language and the Bioconductor environment to make workflows that were "time-efficient and reproducible." After giving some background and then discussing the development and implementation, they conclude that systemPipeR helps researchers "reduce the complexity and time required to translate NGS data into interpretable research results, while a built-in reporting feature improves reproducibility."
Posted on August 20, 2018
By Shawn Douglas
Journal articles
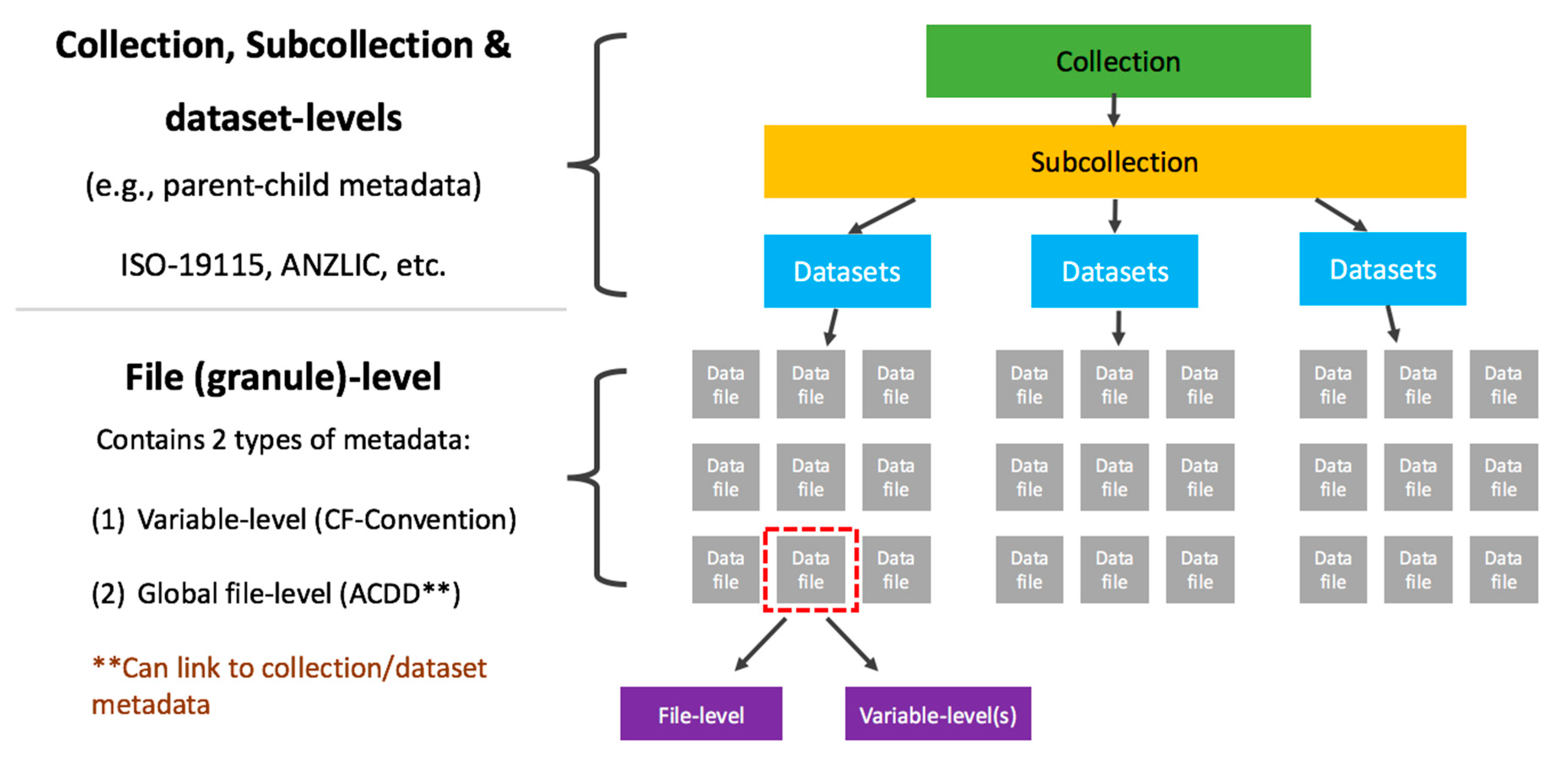
A data quality strategy (DQS) is useful for researchers, organizations, and others, primarily because it allows them "to establish a level of assurance, and hence confidence, for [their] user community and key stakeholders as an integral part of service provision." Evans
et al. of the Australian National University, recognizing this importance, discuss the implementation of their DQS at the Australian National Computational Infrastructure (NCI), detailing their strategy and providing examples in this 2017 paper. They conclude that "[a]pplying the DQS means that scientists spend less time reformatting and wrangling the data to make it suitable for use by their applications and workflows—especially if their applications can read standardized interfaces."
Posted on August 13, 2018
By Shawn Douglas
Journal articles
In this brief opinion article published in
Frontiers in Oncology, Sanders and Showalter turn their thoughts to the rapid-learning health care system (RLHCS), a concept that involves analyzing patient data to make insights in how to improve patient safety, treatment quality, and cost-effectiveness within the health care framework. In combination with comparative effectiveness research (CER) and well-managed big data streams, the RLHCS has the power "to accelerate discovery and the future of individualized radiation treatment planning," they argue. They conclude that big data can "connect a broad range of characteristics to accelerate evidence generation and inform personalized decision-making," and its application through CER and the RLHCS can "accelerate progress in cancer care."
Posted on August 7, 2018
By Shawn Douglas
Journal articles

In this 2018 paper published in
Sensors, e Silva
et al. "highlight the importance of positioning features for [internet of things] applications and [provide] means of comparing and evaluating different connectivity protocols in terms of their positioning capabilities." Noting a lack of research on the topic of IoT connectivity solutions and how they are localized and tracked, the researchers present what related work there is on the topic, discuss positioning domains and systems, compare IoT technologies and enablers., and provide several case studies. They conclude "that power-domain positioning currently offers the best trade-off between implementation cost and positioning accuracy for low-power systems."
Posted on July 30, 2018
By Shawn Douglas
Journal articles
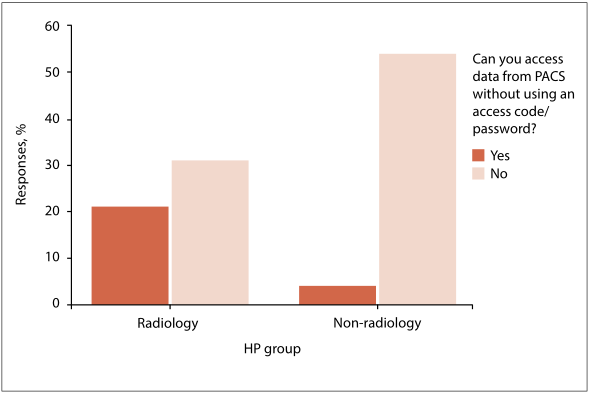
Of course, keeping personal health information protected is important, but what challenges exist to this point in the highly busy and time-sensitive setting of the emergency medical setting? At the end of 2017 Mahlaola and van Dyk published an article on this topic in the
South African Journal of Bioethics and Law that "argues that the minimum standards of effective password use prescribed by the information security sector are not suitable to the emergency-driven medical environment, and that their application as required by law raises new and unforeseen ethical dilemmas. " Using the picture archiving and communication system (PACS) as the primary focus, the authors collected survey responses from Johannesburg-based hospital and radiology departments. After analysis and discussion, they conclude that indeed some ethical quandary exists in the fight to protect patient data using passwords while also trying to save lives, particularly in settings where "seconds count."
Posted on July 24, 2018
By Shawn Douglas
Journal articles

How best can we retrieve value from the rich streams of data in our profession, and introduce a solid, systematic process for analyzing that data? Here Kayser
et al. describe such a process from the perspective of data science experts at Ernst & Young, offering a model that "aims to structure and systematize exploratory analytics approaches." After discussing the building blocks for value creation, they suggest a thorough process of developing analytics approaches to data analytics. They conclude that "[t]he process as described in this work [effectively] guides personnel through analytics projects and illustrates the differences to known IT management approaches."
Posted on July 17, 2018
By Shawn Douglas
Journal articles
In this 2018 paper by Murtagh and Devlin, a historical and professional perspective on data science and how collaborative work across multiple disciplines is increasingly common to data science. This "convergence and bridging of disciplines" strengthens methodology transfer and collaborative effort, and the integration of data and analytics guides approaches to data management. But education, research, and application challenges still await data scientists. The takeaway for the authors is that "the importance is noted of how data science builds collaboratively on other domains, potentially with innovative methodologies and practice,"
Posted on July 10, 2018
By Shawn Douglas
Journal articles
Scientists everywhere nod to the power of big data but are still left to develop tools to manage it. This is just as true in the field of agriculture, where practitioners of precision agriculture are still developing tools to do their work better. Leroux
et al. have been developing their own solution, GeoFIS, to better handle geolocalized data visualization and analysis. In this 2018 paper, they use three case studies to show off how GeoFIS visualizes data, processes it, and incorporates associated data (metadata and industry knowledge) for improved agricultural outcomes. They conclude that the software fills a significant gap while also promoting the adoption of precision agriculture practices.
Posted on July 2, 2018
By Shawn Douglas
Journal articles
In this 2017 paper published in the
Data Science Journal, University of Oxford's Louise Bezuidenhout makes a case for how local challenges with laboratory equipment, research speeds, and design principles hinder adoption of open data policies in resource-strapped countries. Noting that "openness of data online is a global priority" in research, Bezuidenhout uses interviews in various African countries and corresponding research to draw conclusions that many in high-income countries may not. The main conclusion: "Without careful and sensitive attention to [the issues stated in the paper], it is likely that [low- and middle-income country] scholars will continue to exclude themselves from opportunities to share data, thus missing out on improved visibility online."
Posted on June 26, 2018
By Shawn Douglas
Journal articles
In this educational journal article published in
PLoS Computational Biology, Cole and Moore of the University of Pennsylvania's Institute for Biomedical Informatics offer 11 tips for health informatics researchers and practitioners to embrace in improving reproducibility, knowledge sharing, and costs: adopt cloud computing. The authors compare more traditional "in-house enterprise compute systems such as high-performance computing (HPC) clusters" located in academic institutions with more agile cloud computing installations, showing various ways researchers can benefit from building biomedical informatics workflows on the cloud. After sharing their tips, they conclude that "[c]loud computing offers the potential to completely transform biomedical computing by fundamentally shifting computing from local hardware and software to on-demand use of virtualized infrastructure in an environment which is accessible to all other researchers."
Posted on June 18, 2018
By Shawn Douglas
Journal articles
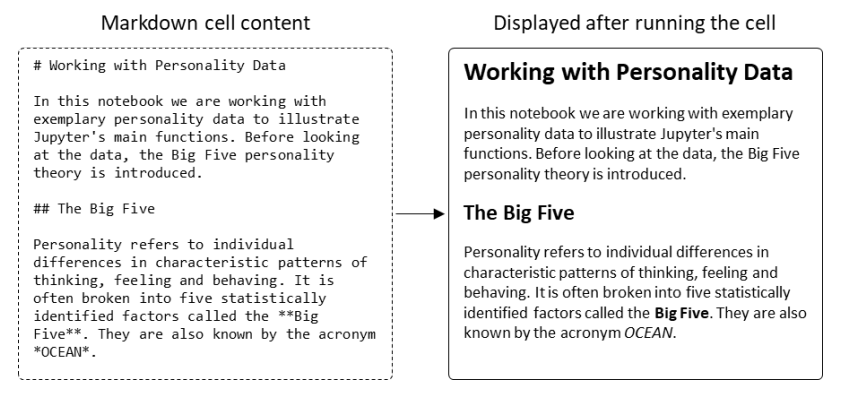
Jupyter Notebook, an open-source interactive web application for the data science and scientific computing community (and with some of the features of an electronic laboratory notebook), has been publicly available since 2015, helping scientists make computational records of their research. In this 2018 tutorial article by Friedrich-Schiller-Universität Jena's Phillipp Sprengholz, the installation procedures and features are presented, particularly in the context of aiding psychological researchers with their efforts in making research more reproducible and shareable.
Posted on June 12, 2018
By Shawn Douglas
Journal articles
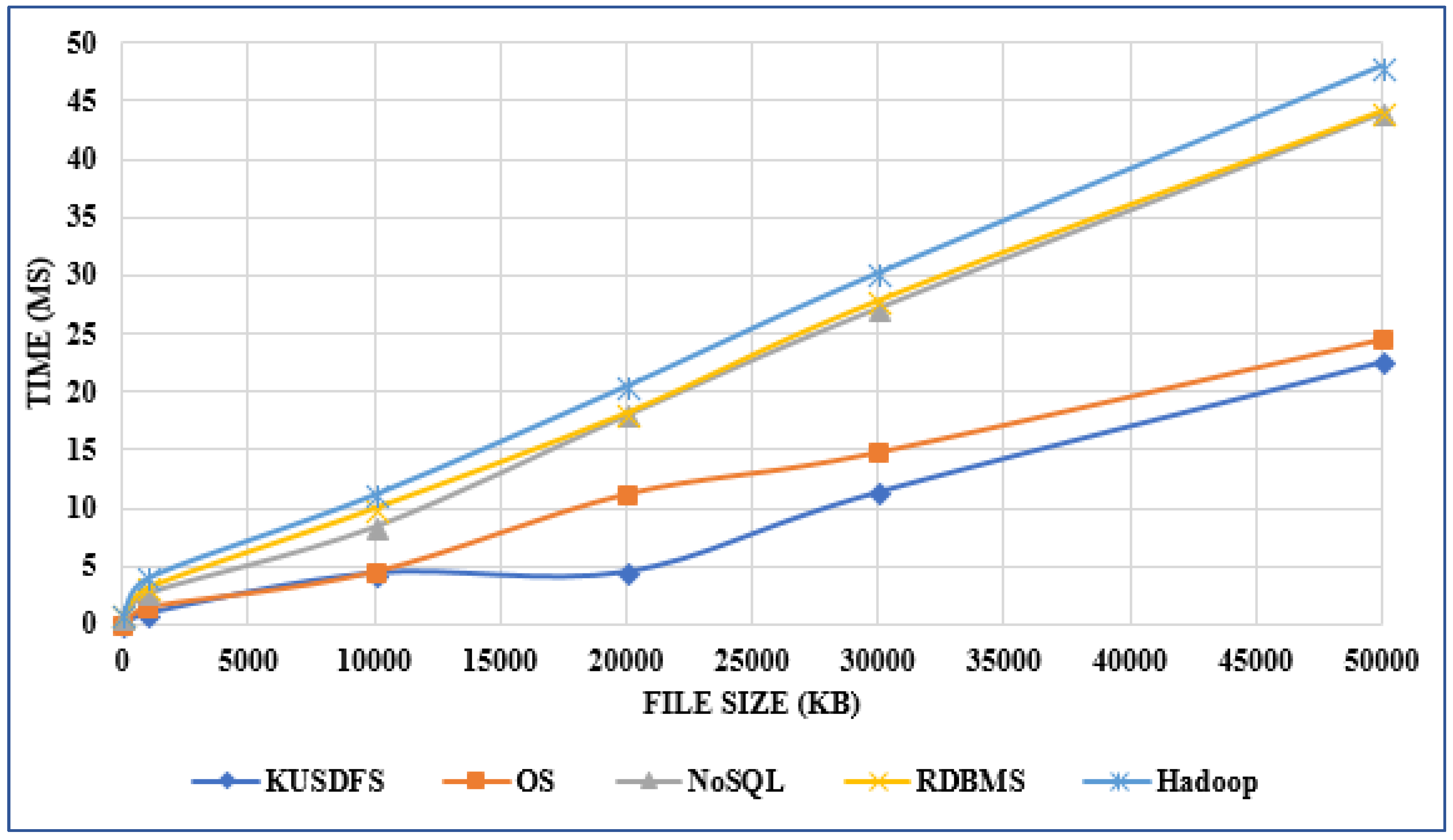
There's been plenty of talk about big data management over the past few years, particularly in the domain of software-based management of said data. But what of the IT infrastructure, particularly in the world of heathcare, where file size and number continue to grow? Ergüzen and Ünver describe in this 2018 paper published in
Applied Sciences how they researched and developed a modern file system structure that handles the intricacies of big data in healthcare for Kırıkkale University. After discussing big data problems and common architectures, the duo lay out the various puzzle pieces that make up their file system, reporting system performance "97% better than the NoSQL system, 80% better than the RDBMS, and 74% better than the operating system" via improvements in read-write performance, robustness, load balancing, integration, security, and scalability.
Posted on June 1, 2018
By Shawn Douglas
Journal articles

In this 2018 paper published in the
International Journal of Interactive Multimedia and Artificial Intelligence , Baldominos
et al. present DataCare, a scalable healthcare data management solution built on a big data architecture to improve healthcare performance, including patient outcomes. Designed to provide "a complete architecture to retrieve data from sensors installed in the healthcare center, process and analyze it, and finally obtain relevant information, which is displayed in a user-friendly dashboard," the researchers explain the architecture and how it was evaluated in a real-life facility in Madrid, Spain. They also explain how key performance indicators are affected and how the system could be improved in the future.
Posted on May 29, 2018
By Shawn Douglas
Journal articles
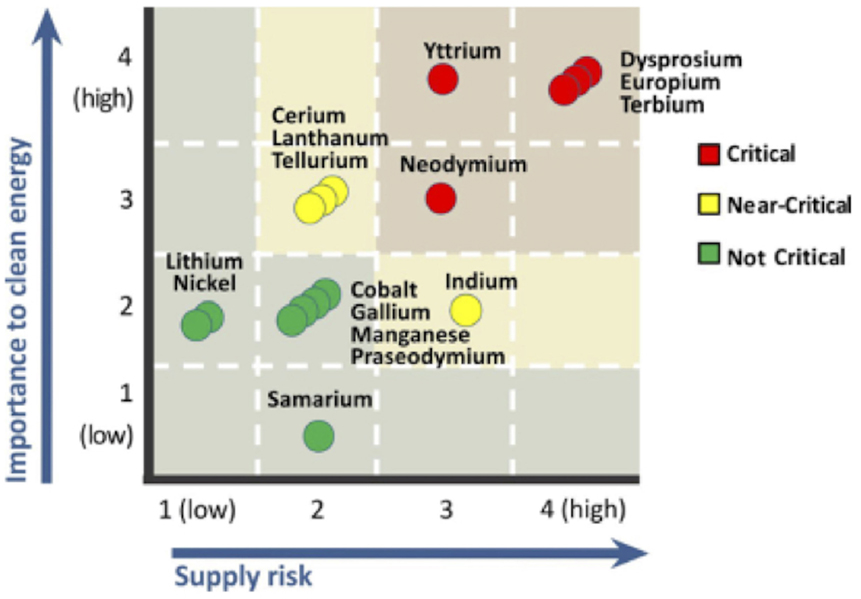
Text analytics is a data analysis technique that is used in several industries to develop new insights, make new discoveries, and improve operations. This should be applicable to materials scientists and informaticists also, say Kalathil
et al. in this 2018 paper published in
Frontiers in Research Metrics and Analytics. Using a coclustering text analysis technique and custom tools, the researchers demonstrate how others can "better understand how specific components or materials are involved in a given technology or research stream, thereby increasing their potential to create new inventions or discover new scientific findings." In their example, they reviewed nearly 438,000 titles and abstracts to examine 16 materials, allowing them to "associate individual materials with specific clean energy applications, evaluate the importance of materials to specific applications, and assess their importance to clean energy overall."
Posted on May 21, 2018
By Shawn Douglas
Journal articles
What is "information management"? How is it used in the context of research papers across a wide variety of industries and scientific disciplines? How do the definitions vary, and can an improved definition be created? Ladislav Buřita of the University of Defense in Brno attempts to answer those questions and more in this 2018 paper published in the
Journal of Systems Integration.
Posted on May 15, 2018
By Shawn Douglas
Journal articles
Cao
et al. describe their design
and methodology used in constructing a system of tighter data integration for pharmaceutical research and manufacturing in this 2018 paper published in
Process. Recognizing the "integration of data in a consistent, organized, and reliable manner is a big challenge for the pharmaceutical industry," the authors developed an ontological information structure relying on the ANSI/ISA-88 batch control standard, process control systems, a content management systems, a purpose-built electronic laboratory notebook, and cloud services, among other aspects. The authors conclude, after describing two use cases, that "data from different process levels and distributed locations can be integrated and contextualized with meaningful information" with the help of their information structure, allowing "industrial practitioners to better monitor and control the process, identify risk, and mitigate process failures."
Posted on May 7, 2018
By Shawn Douglas
Journal articles
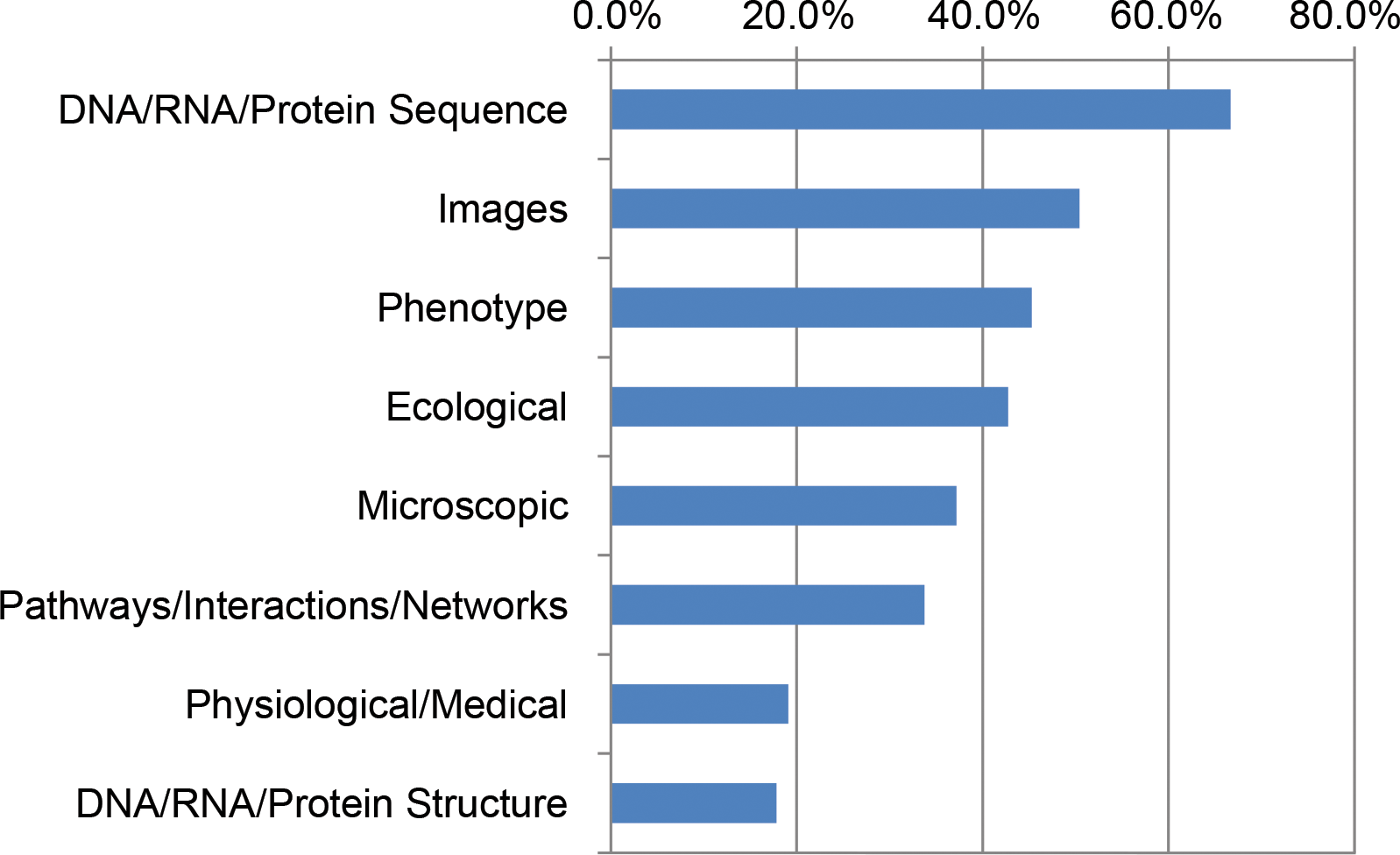
In this brief education article published in
PLOS Computational Biology, Barone
et al. present the results of a survey of funded National Science Foundation (NSF) Biological Sciences Directorate principal investigators and how/if their computational needs were being met. Citing several other past surveys and reports, the authors describe the state of cyberinfrastructure needs as they understood them before their survey. Then they present their results. "Training on integration of multiple data types (89%), on data management and metadata (78%), and on scaling analysis to cloud/HPC (71%) were the three greatest unmet needs," they conclude, also noting that while hardware isn't a bottleneck, a "growing gap between the accumulation of big data and researchers’ knowledge about how to use it effectively" is concerning.
Posted on May 1, 2018
By Shawn Douglas
Journal articles
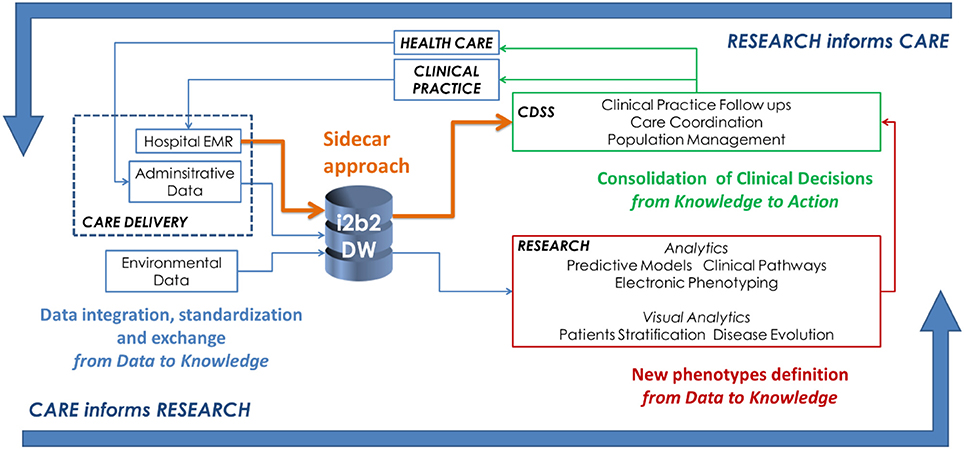
What happens when you combine clinical big data tools and data with clinical decision support systems (CDSS)? In this 2018 journal article published in
Frontiers in Digital Humanities, Dagliati
et al. report two such effective implementations affecting diabetes and arrhythmogenic disease research. Through the lens of the "learning healthcare system cycle," the authors walk through the benefits of big data tools to clinical decision support and then provide their examples of live use. They conclude that through the use of big data and CDDS, "when information is properly organized and displayed, it may highlight clinical patterns not previously considered ... [which] generates new reasoning cycles where explanatory assumptions can be formed and evaluated."






