Posted on February 20, 2017
By John Jones
Journal articles
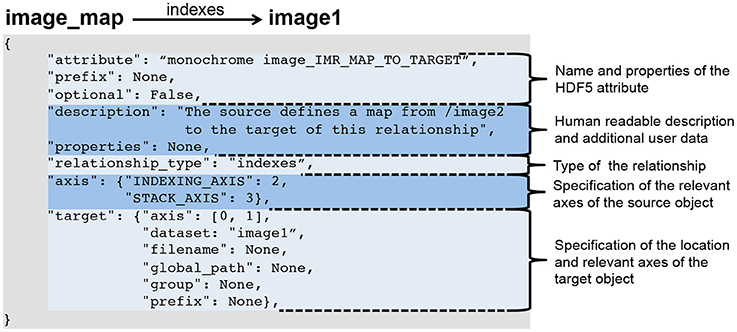
Neuroscience, like so many fields of science, is swimming in data, much of it in differing formats. This creates barriers to data sharing and project enactment. Rübel
et al. argue that standardization of neuroscience data formats can improve analysis and sharing efforts. "Arguably, the focus of a neuroscience data standard should be on addressing the application-centric needs of organizing scientific data and metadata, rather than on reinventing file storage methods," they state. This late 2016 paper, published in
Frontiers of Neuroinformatics, details their effort to make such a standardized framework, called BRAINformat, one that "fill[s] important gaps in the portfolio of available tools for creating advanced standards for modern scientific data."
Posted on February 14, 2017
By John Jones
Journal articles
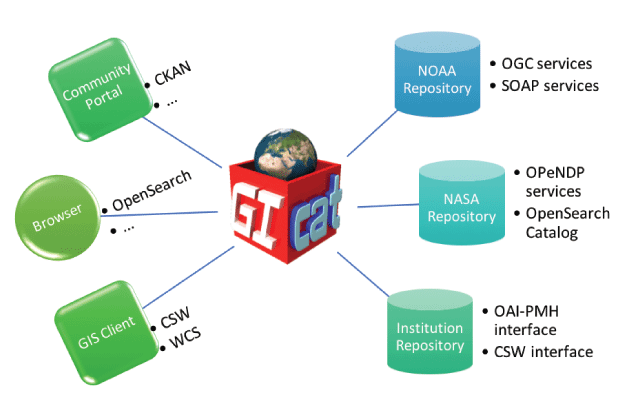
This 2017 paper by University of Colorado's Siri Jodha Singh Khalsa, published in
Data Science Journal, provides background on the successes, challenges, and outcomes of the Brokering Building Block (BCube) project, which aims "to provide [geo]scientists, policy makers and the public with computing resources, analytic tools and educational material, all within an open, interconnected and collaborative environment." It describes the processes of infrastructure development, interoperability design, data testing, and lessons learned from the process, including an analysis of the human elements involved in making data sharing easier and more profound.
Posted on February 8, 2017
By John Jones
Journal articles

Turnkey data repositories such as DSpace have been evolving over the past decade, from housing publication preprints and postprints to today handling actual data management tasks of research. But what if this evolving technology could further be improved "to improve the discoverability of the deposited data"? Harvey
et al. of the Imperial College London explored this topic in their 2017 paper published in
Journal of Cheminformatics, developing new insights into repository design and DataCite metadata schemes. They published their results hoping that it "may in turn assist researchers wishing to deposit data in identifying the repository attributes that can best expose the discoverability and re-use of their data."
Posted on January 31, 2017
By John Jones
Journal articles
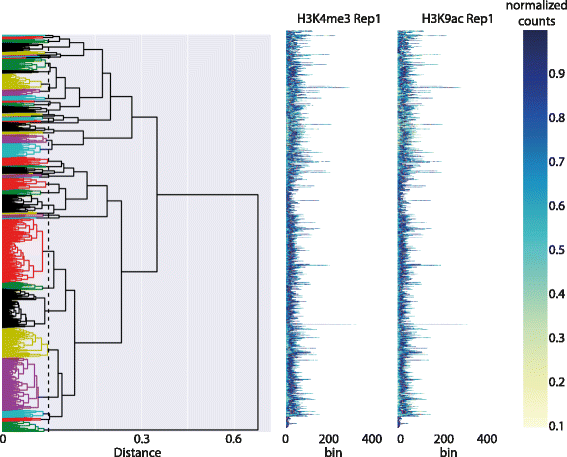
Lukauskas
et al. present their open-source software package DGW (Dynamic Gene Warping) in this December 2016 paper published in
BMC Informatics. Used for the "simultaneous alignment and clustering of multiple epigenomic marks," the software uses a process called dynamic time warping (DTW) to capture epigenomic mark structure. The authors conclude that their research shows "that DGW can be a practical and user-friendly tool for exploratory data analysis of high-throughput epigenomic data sets" and demonstrates "potential as a useful tool for biological hypothesis generation."
Posted on January 24, 2017
By John Jones
Journal articles

In this short paper published in December 2016, Hiner
et al. of the University of Wisconsin at Madison demonstrate their open-source library SCIFIO (SCientific Image Format Input and Output). Built on inspiration from the Bio-Formats library for microscopy image data, SCIFIO attempts to act as "a domain-independent image I/O framework enabling seamless and extensible translation between image metadata models." Rather than fight with the difficulties of repeating experiments based on data in proprietary formats, SCIFIO's open-source nature help with reproducibility of research results and proves "capable of adapting to the demands of scientific imaging analysis."
Posted on January 17, 2017
By John Jones
Journal articles
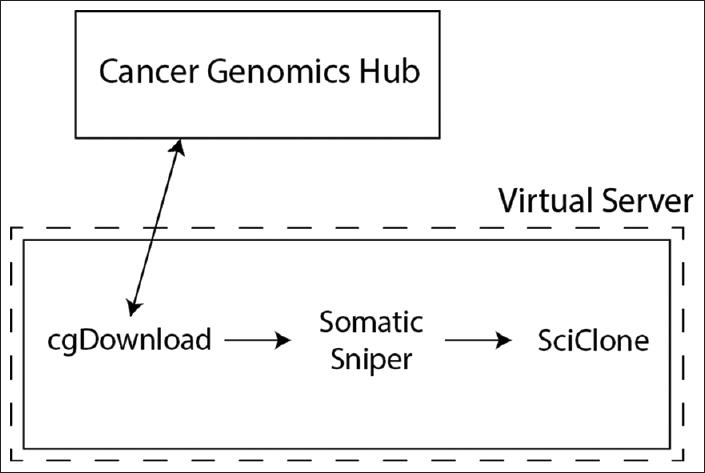
As technology progresses, it allows bioinformaticians to improve the efficiency of their data processing tools and provide better solutions for patient care. As this December 2016 paper by Schulz
et al. points out, one way in which dramatic change can potentially occur in science's big data management is through the use of application virtualization. The researchers, based out of Yale, attempt to "demonstrate the potential benefits of containerized applications and application workflows for computational genomics research." They conclude this technology has the potential to "improve pipeline and experimental reproducibility since preconfigured applications can be readily deployed to nearly any host system."
Posted on January 12, 2017
By John Jones
Journal articles, Uncategorized

This brief non-peer-reviewed article by Sanjay Joshi, Isilon CTO of Healthcare and Life Sciences at the Dell EMC Emerging Technologies Team, looks at the global state of imaging in oncology clinical trials. His message? "[C]linical trials need to scale this critical imaging infrastructure component (the VNA) globally as a value-add and integrate it with clinical trials standards like the Clinical Data Interchange Standards Consortium (CDISC) along with the large ecosystem of applications that manage trials." In other words, standards, security, and scale are as important as ever in dealing with data, and clinical imaging is no exception.
Posted on January 11, 2017
By John Jones
Journal articles
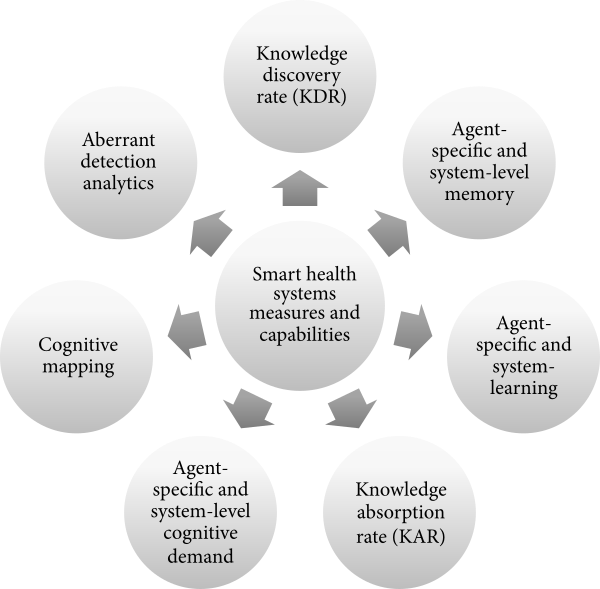
In this 2017 paper published in
Computational and Mathematical Methods in Medicine, Carney and Shea of the Gillings School of Global Public Health at University of North Carolina - Chapel Hill take a closer look at what drives intelligent public health system characteristics, and they provide insights into measures and capabilities vital to the public health informatician. They conclude that "[a] common set of analytic measures and capabilities that can drive efficiency and viable models can demonstrate how incremental changes in smartness generate corresponding changes in public health performance." This work builds on existing literature and seeks "to establish standardized measures for smart, learning, and adaptive public health systems."
Posted on January 4, 2017
By John Jones
Journal articles
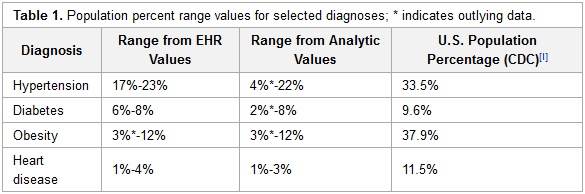
Hartzband and Jacobs of the RCHN Community Health Foundation, a U.S. non-profit dedicated to support the operations of community health centers (CHCs), provide the results of their data analysis of CHCs and EHR data in this 2016 paper published in the
Online Journal of Public Health Informatics. Hoping "[t]o better understand existing capacity and help organizations plan for the strategic and expanded uses of data" for the support of operations and clinical practice, the researchers looked at CHCs' EHR-derived and stack analytic results. The concluded that "[d]ata awareness ... needs to be prioritized and developed by health centers and other healthcare organizations if analytics are to be used in an effective manner to support strategic objectives."
Posted on December 20, 2016
By John Jones
Journal articles

In this short paper, Williams
et al. of the University of Michigan provide a brief technical view of microservices and how they have the potential to improve the organization and use of bioinformatics and other healthcare applications. They propose that "a well-established software design and deployment strategy" that uses micorservices framework can improve the collaborative and patient-focused efforts of researchers and laboratorians everywhere. They conclude that bioinformaticians, pathologists, and other laboratorians "can contain ever-expanding IT costs, reduce the likelihood of IT implementation mishaps and failures, and perhaps most importantly, greatly elevate the level of service" with properly implemented microservice-based versions of the software they use.
Posted on December 12, 2016
By John Jones
Journal articles
In this brief paper published in 2016, Wolske and Rhinesmith present what they call "a set of critical questions" for guiding those delving into a community informatics (CI) project. Properly using technology that allows collaboration, popular education, and asset development tools, community informatics projects are able to carry on with the primary goal of sustainably supporting community development projects. However, the authors argue, a set of ethical questions should be asked to drive the planning, development, and implementation of said CI projects. These questions, presented in this paper, have the potential to better "guide the evolution of ethical community informatics in practice, as well as the personal transformation of CI practitioners who seek to embrace all as equals and experts."
Posted on December 7, 2016
By John Jones
Journal articles
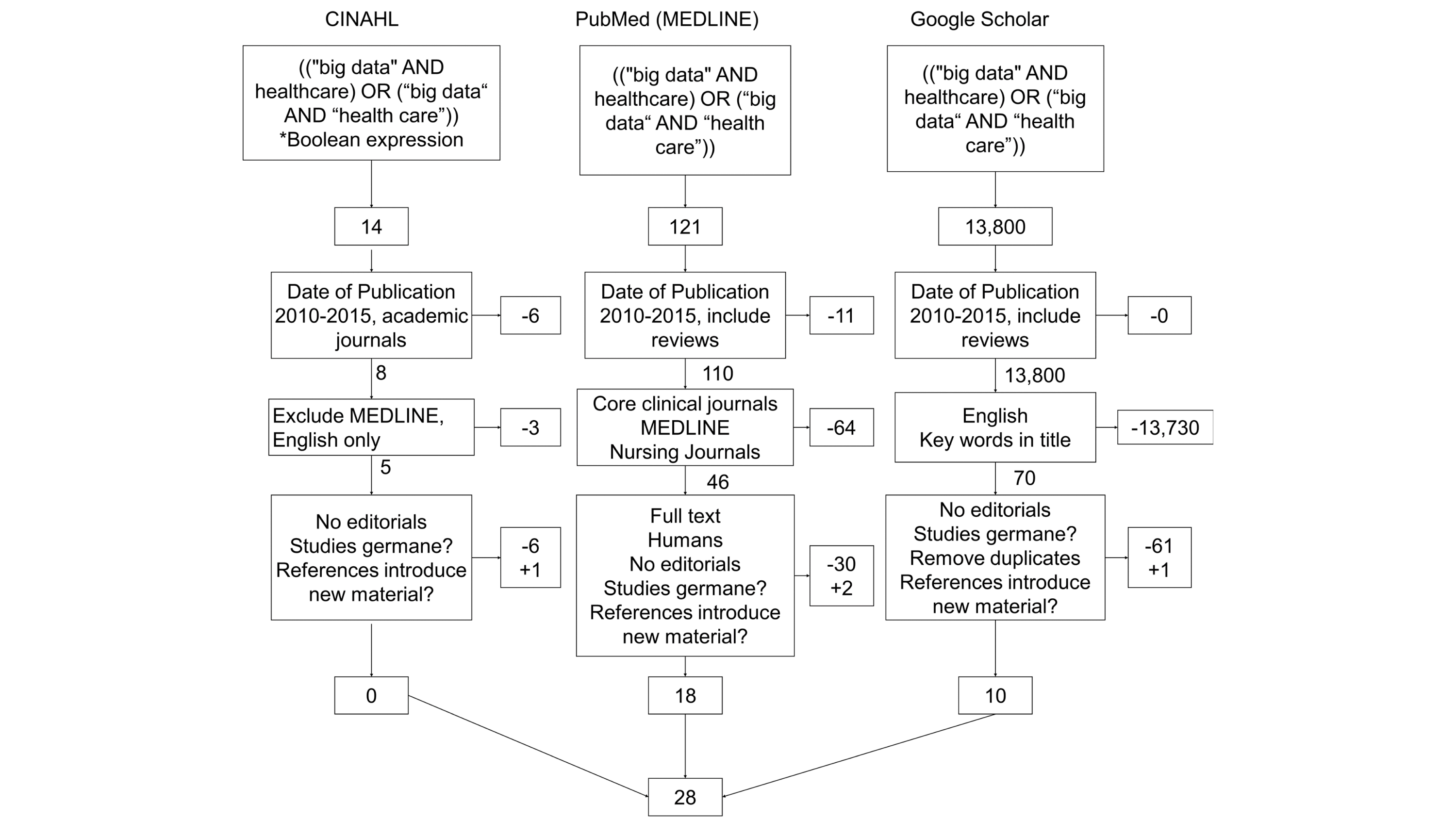
In this 2016 article published in
JMIR Medical Informatics, Kruse
et al. of the Texas State University present the results of a systematic review of articles and studies involving big data in the health care sphere. From this review the team identified nine challenges and 11 opportunities that big data brings to health care. The group describes these challenges and opportunities, concluding that either way "the vast amounts of information generated annually within health care must be organized and compartmentalized to enable universal accessibility and transparency between health care organizations."
Posted on November 28, 2016
By John Jones
Journal articles

Moving data between systems via an electronic exchange (interoperability) while keeping it clean is always a challenge. Data exchanged between electronic health records (EHR) and immunization information system (IIS) is no exception, as Woinarowicz and Howell demonstrate in this 2016 paper published in
Online Journal of Public Health Informatics. Working for the North Dakota Department of Health, Division of Disease Control, the duo explain how setting up their IIS for interoperability with provider EHRs "has had an impact on NDIIS data quality." They conclude: "Timeliness of data entry has improved and overall doses administered have remained fairly consistent, as have the immunization rates ... [but more] will need to be done by NDIIS staff and its vendor to help reduce the negative impact of duplicate record creation, as well as data completeness."
Posted on November 21, 2016
By John Jones
Journal articles
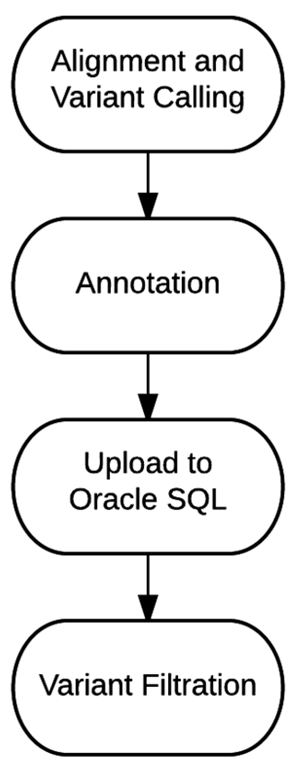
Genomic data is increasingly used to provide better, more focused clinical care. Or course, its associated datasets can be large, and it can take significant processing power to utilize and manage effectively. In this 2016 paper published in
Journal of Personalized Medicine, Tsai
et al. of Partners Healthcare describe their "bioinformatics strategy to efficiently process and deliver genomic data to geneticists for clinical interpretation." They conclude that with more research comes improved workflows and "filtrations that include larger portions of the non-coding regions as they start to have utility in the clinical setting, ultimately enabling the full utility of complete genome sequencing."
Posted on November 16, 2016
By John Jones
Journal articles
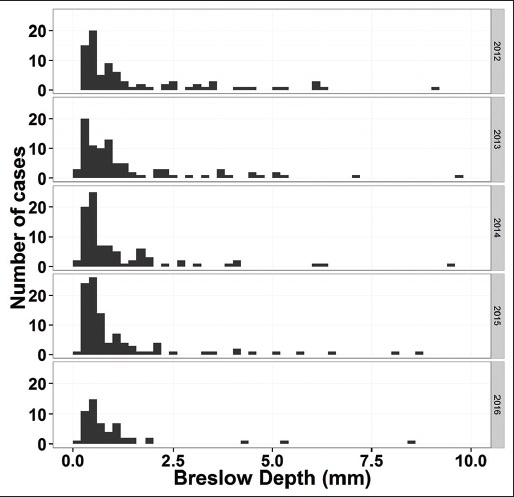
Synoptic reporting is an important part of not only managing patient testing information but also reporting that data for research and data mining purposes. As such, the extraction of particular elements from these types of reports — including those recording major cancer information — has historically been difficult. Recent developments in extracting key information from synoptic reports have made it easier, however, including the use of the R programming language. In this paper by J.J. Ye, the process of extracting melanoma data from pathology datasets is used to describe a broader, wide-ranging application of R and the associated RODBC package for extracting useful data from synoptic reports. Ye concludes: "This approach can be easily modified and adopted for other pathology information systems that use relational database for data management."
Posted on November 10, 2016
By John Jones
Journal articles
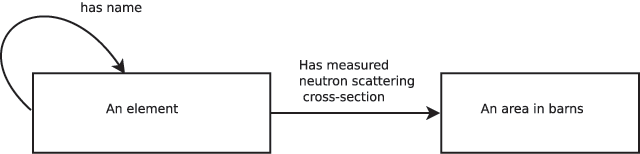
In this 2016 paper published in
Data Science Journal, Australian researcher James Hester provides "a simple formal approach when developing and working with data standards." Using ontology logs or "ologs" — category-theoretic box and arrow diagrams that visually explains mapping elements of sets — and friendly file formats, adapters, and modules, Hester presents several applications towards a useful scientific data transfer network. He concludes: "These ontologies nevertheless capture all scientifically-relevant prior knowledge, and when expressed in machine-readable form are sufficiently expressive to mediate translation between legacy and modern data formats." This results in "a modular, universal data file input and translation system [that] can be implemented without the need for an intermediate format to be defined."
Posted on November 2, 2016
By John Jones
Journal articles
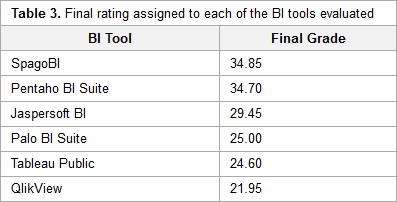
Brandão
et al. at the University of Minho in Portugal needed a practical business intelligence (BI) solution for the Centro Materno Infantil do Norte (CMIN) hospital, particularly to assist with tasks related to gynecology and obstetrics (GO) and voluntary interruption of pregnancy (VIP). In particular, the group needed "to visualize the knowledge extracted from the data stored in information systems in CMIN, through their representation in tables, charts, and tables, among others, but also by integrating DM predictive models." The group set about researching various options, documenting their process along the way. This journal article, published in late 2016, walks through the entire evaluation process, providing a glimpse of how BI applications are relevant to the healthcare industry.
Posted on October 25, 2016
By John Jones
Journal articles
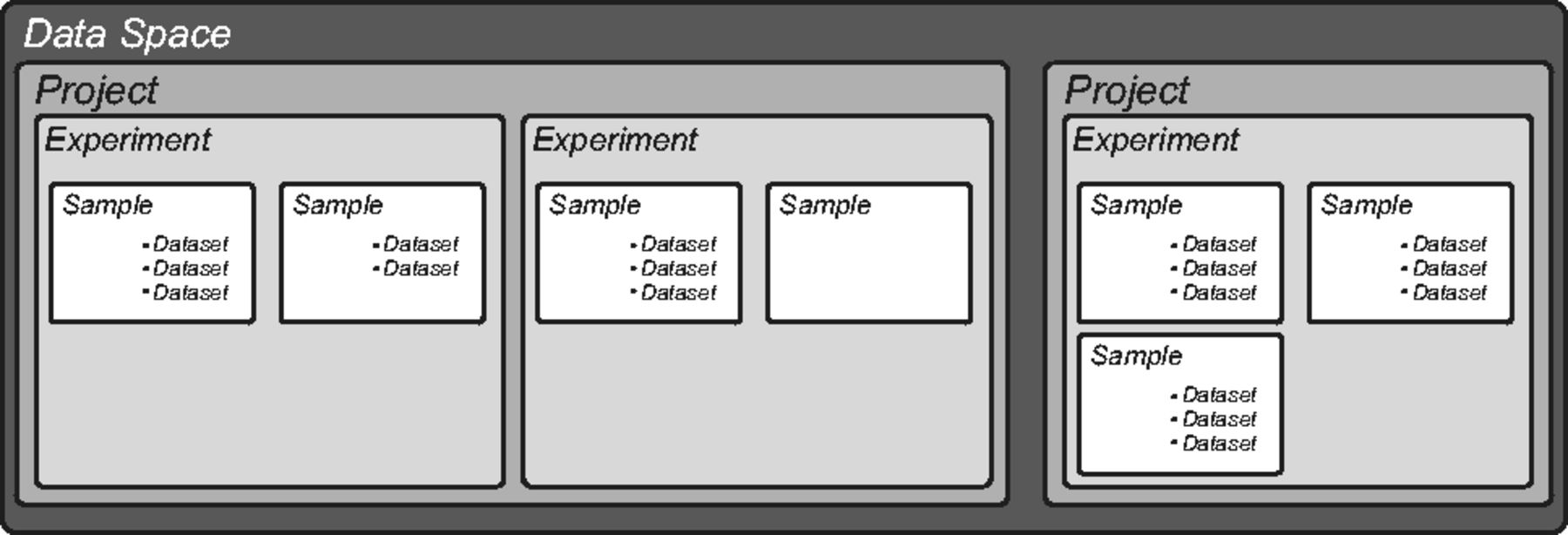
Researchers at ETH Zürich, finding that many commercial laboratory informatics options "affordable to academic labs had either unsuitable user interfaces (UI) or lack of features," decided to look at open-source options. However, like others, they also found some pure open-source options lacked necessary regulatory and high-throughput support. Barilliari
et al. decided to go the "build your own" route, expanding on the existing openBIS platform and adding laboratory information management system (LIMS) and electronic laboratory notebook (ELN) functionality. This brief paper, published in late 2015 in
Bioinformatics, gives a quick overview of the software and how it operates.
Posted on October 18, 2016
By John Jones
Journal articles
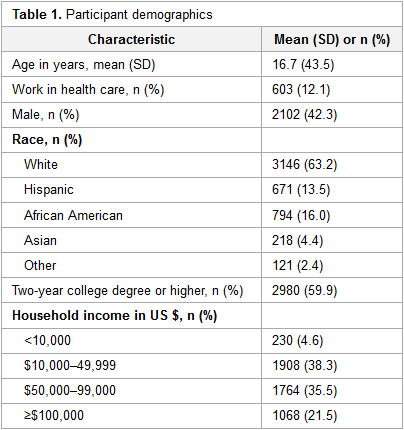
In this 2016 paper published in the
Journal of Medical Internet Research, Mackert
et al. review the state of patients' health literacy and how it relates to perceived ease-of-use and the usefulness of the health technology used. The group asked study participants about experiences with fitness apps, nutrition apps, activity trackers, and patient portals, noting afterwards an association between HIT adoption and higher health literacy. They conclude that "HIT has tremendous potential to improve the health of users, and this study is a crucial step toward better understanding how health literacy is associated with HIT adoption and ensuring that users of all levels of health literacy can realize those benefits."
Posted on October 12, 2016
By John Jones
Journal articles
In the various domains of scientific research — including computational biology — the need for better visualization of experimental and research data continues to grow. Whether it's home-grown solutions or open-source solutions, software that can take a wide variety of data and quickly output it in a visualization such as a Venn or Euler diagram is a useful commodity. In this 2016 paper published in
BMC Bioinformatics, researchers at the Ontario Institute for Cancer Research outline their R-friendly, integrable creation VennDiagramWeb, which "allows real-time modification of Venn and Euler diagrams, with parameter setting through a web interface and immediate visualization of results."






