Posted on December 22, 2020
By LabLynx
Journal articles
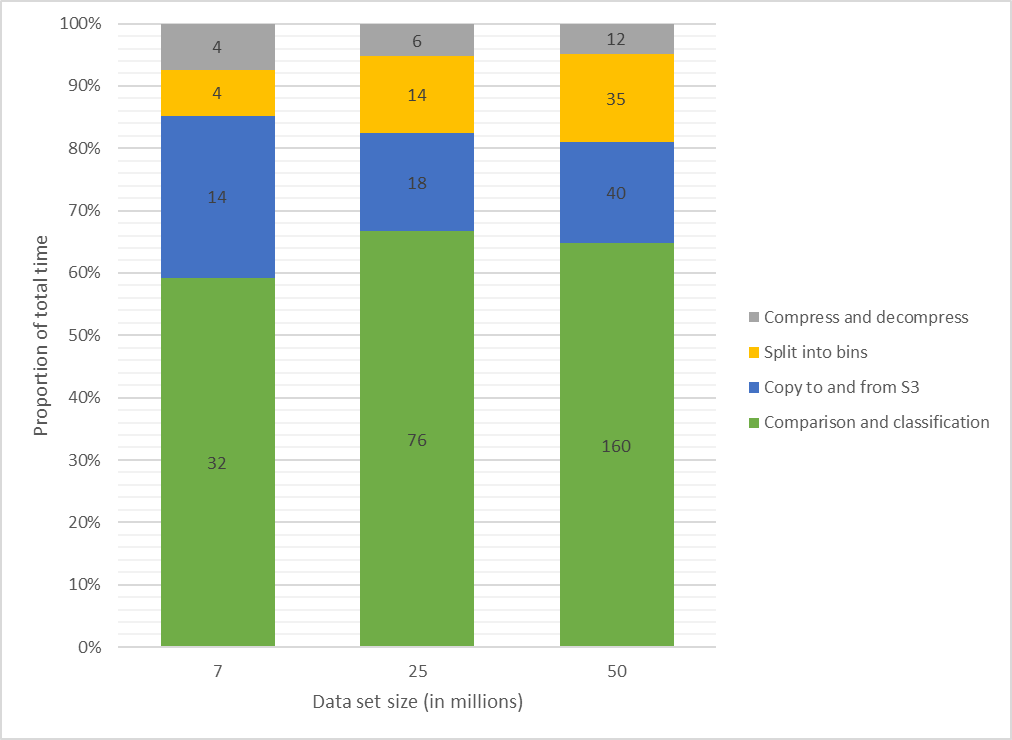
This 2020 paper published in
JMIR Medical Informatics examines both the usefulness of linked data (connecting data points across multiple data sets) for investigating health and social issues, and a cloud-based means for enabling linked data. Brown and Randall briefly review the state of cloud computing in general, and in particular with relation to data linking, noting a dearth of research on the practical use of secure, privacy-respecting cloud computing technologies for record linkage. Then the authors describe their own attempt to demonstrate a cloud-based model for record linkage that respects data privacy and integrity requirements, using three synthetically generated data sets of varying sizes and complexities as test data. They discuss their findings and then conclude that through the use of "privacy-preserving record linkage" methods over the cloud, data "privacy is maintained while taking advantage of the considerable scalability offered by cloud solutions," all while having "the ability to process increasingly larger data sets without impacting data release protocols and individual patient privacy" policies.
Posted on December 15, 2020
By LabLynx
Journal articles
In this 2020 paper published in
Data Science Journal, Mayernik
et al. present their take on assessing risks to digital and physical data collections and archives, such that the appropriate resource allocation and priorities may be set to ensure those collections' and archives' future use. In particular, they present their data risk assessment matrix and its use in three different use cases. Noting that the trust placed in a data repository and how it's run is "separate and distinct" from trust placed in the data itself, the authors lay out the steps for assessing those repositories' risks, and then making that task easier through their risk assessment matrix. After presenting their use cases, they conclude that their matrix proves "a lightweight method for data collections to be reviewed, documented, and evaluated against a set of known data risk factors."
Posted on December 8, 2020
By LabLynx
Journal articles
While the push for the decriminalization of cannabis, its constituents, and the products made from them continues in the United States, issues of quality control testing and standardization persist. Consistent and accurate laboratory testing of these products is required to better ensure human health outcomes, to be sure. However, with the legalization of hemp, it's not just products intended for humans that are being created from hemp constituents such as cannabidiol (CBD); products marketed for our pets and other animals are appearing. And with them an inconsistent, sometimes dangerous lack of testing controls, or so finds Wakshlag et al. in this 2020 paper published in Veterinary Medicine: Research and Reports. The researchers review the regulatory atmosphere (or lack thereof) and then present the results of analytically testing 29 cannabis products marketed for dog use. They found wide-swinging variances in actual cannabinoid and contaminant content, straying often from labeled contents and contaminant standards. They conclude "the range and variability of [cannabis-derived] products in the veterinary market is alarming," and given the current state of regulation and standardization, "veterinary professionals should only consider manufacturers providing product safety data such as COAs, pharmacokinetic data, and clinical application data when clients solicit information regarding product selection."
Posted on December 1, 2020
By LabLynx
Journal articles
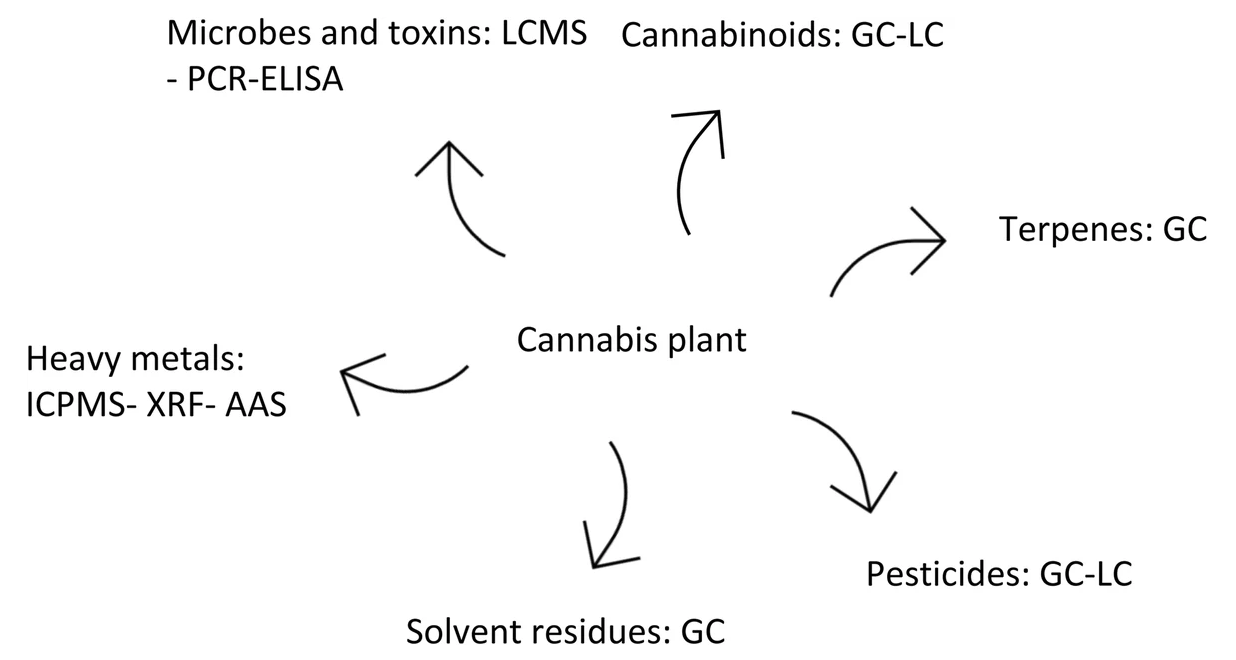
Many papers have been published over the years describing different methods for quantifying the amount of cannabinoids in
Cannabis sativa and other phenotypes, as well as the products made from them. Few have taken to the task of reviewing all such methods while weighing their pros and cons. This 2020 paper by Lazarjani
et al. makes that effort, landing on approximately 60 relevant papers for their review. From gas chromatography to liquid chromatography, as well as various spectrometry and spectroscopy methods, the authors give brief review of many methods and their combinations. They conclude that high-performance liquid chromatography-tandem mass spectrometry (HPLC-MS/MS) likely has the most benefits when compared to other methods reviewed in this paper, including the ability to "differentiate between acidic and neutral cannabinoids" and "differentiate between different cannabinoids based on the m/z value of their molecular ion," while having "more specificity when compared to ultraviolet detectors," particularly when dealing with complex matrices.
Posted on November 25, 2020
By LabLynx
Journal articles
In this 2020 paper published in
Molecules, Izzo
et al. describe one of the first efforts to comprehensively analyze the polyphenol content of the inflorescences of
Cannabis sativa L. Noting the rise of polyphenol-containing products due to polyphenols' reported health benefits, the researchers found a dearth of research analyzing them in the flowers of
Cannabis sativa L. The authors describe their use of ultra high-performance liquid chromatography–quadrupole–orbitrap high-resolution mass spectrometry, as well as other spectrophotometric methods, to identify and quantify the polyphenols from four major cultivars in Italy. Of note was the Selected Carmagnola (CS) cultivar, which reliably contained the highest amount of many of the discovered polyphenols. They conclude that their results highlight the need for further research into the inflorescences of
Cannabis sativa L. cultivars for polyphenols "to estimate their efficacy for future applications for nutraceutical purposes."
Posted on November 17, 2020
By LabLynx
Journal articles
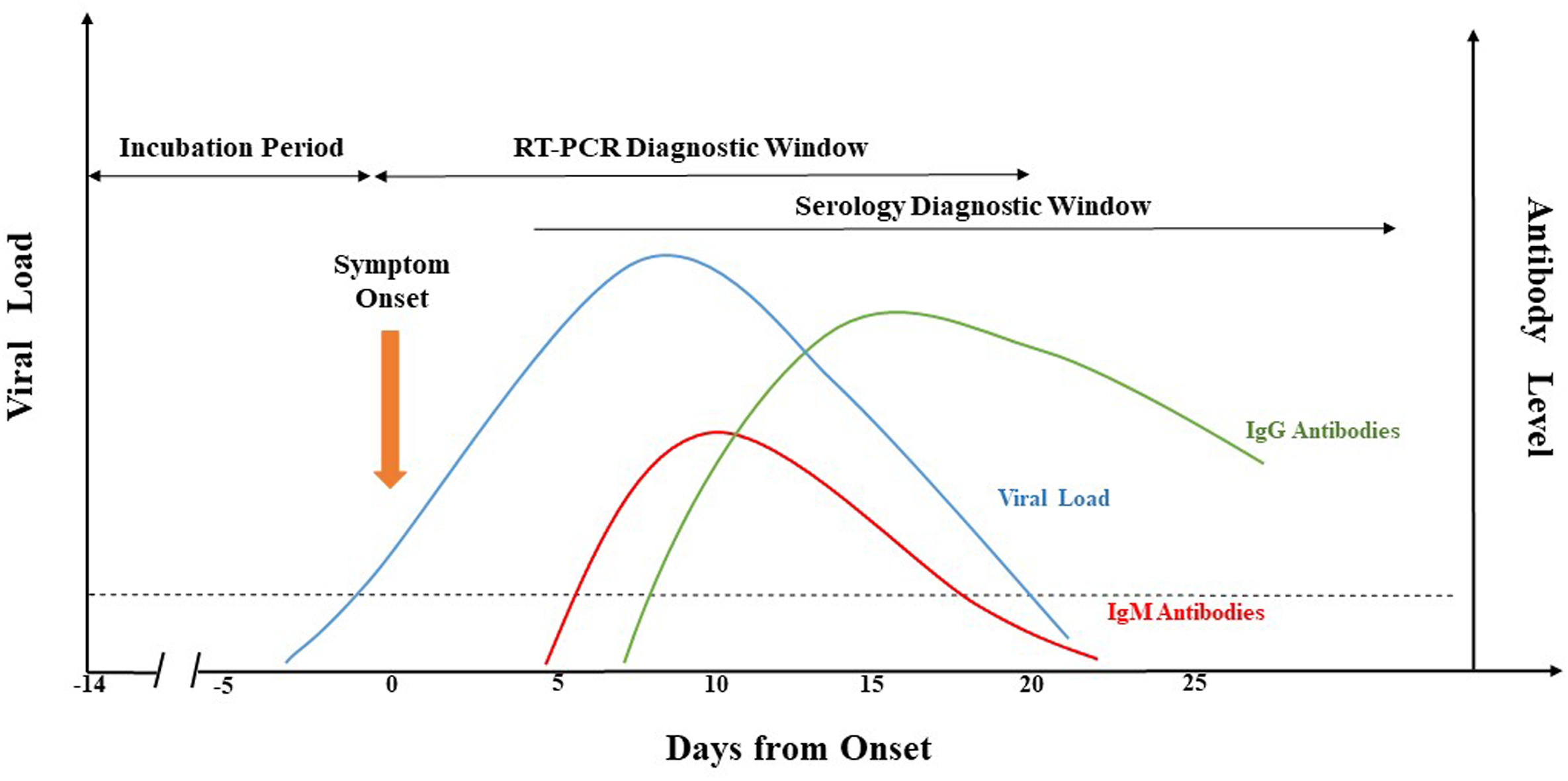
What is the current state of laboratory testing methods for SARS-CoV-2, the virus that causes COVID-19? This perspective paper from China (submitted for approval in September 2020), published in
Journal of Microbiology, Immunology and Infection, analyzes and describes the latest with how laboratories in China approach testing for the virus in the human population. Jing
et al. first introduce background about the pandemic, as well as the etiological characteristics and genome organization of SARS-CoV-2. Then they dive into the common molecular methods used, including qRT-PCR, LAMP, CRISPR, genome sequencing, and nucleic acid mass spectrometry. The authors then analyze the various challenges with keeping such testing consistent, categorically addressing seven areas where false-negative results arise. They close with the benefits (and drawbacks) of supplemental serological testing, before concluding "more comprehensive analysis and/or further evaluation of different diagnostic methods" is still required to improve identification rates.
Posted on November 10, 2020
By LabLynx
Journal articles
In this 2020 article published in
Practical Laboratory Medicine, Angela Fung of St. Paul’s Hospital and the University of British Columbia reviews how point-of-care testing (POCT) in healthcare organizations can be improved with informatics tools, as well as how those tools aid those organizations in maintaining regulatory compliance. After a brief introduction to the concept of POCT, Fung discusses how not only electronic medical record (EMR) systems and POCT devices go hand-in-hand, but also how interfacing to other systems such as laboratory information systems (LIS) and hospital information systems (HIS) reduces documentation and data entry errors. She also discusses at length the important features required of any data management system (DMS) used in combination with POCT devices, as well as the resources required to support those DMSs. Fung ends with the personnel side of POCT, and how such POCT programs could be better managed under the context of DMSs. The conclusion? "Connectivity and DMS are essential tools in improving the accessibility and ability to manage POCT programs efficiently," and " effective management of POCT programs ultimately relies on building relationships, collaborations, and partnerships" among stakeholders.
Posted on November 2, 2020
By LabLynx
Journal articles
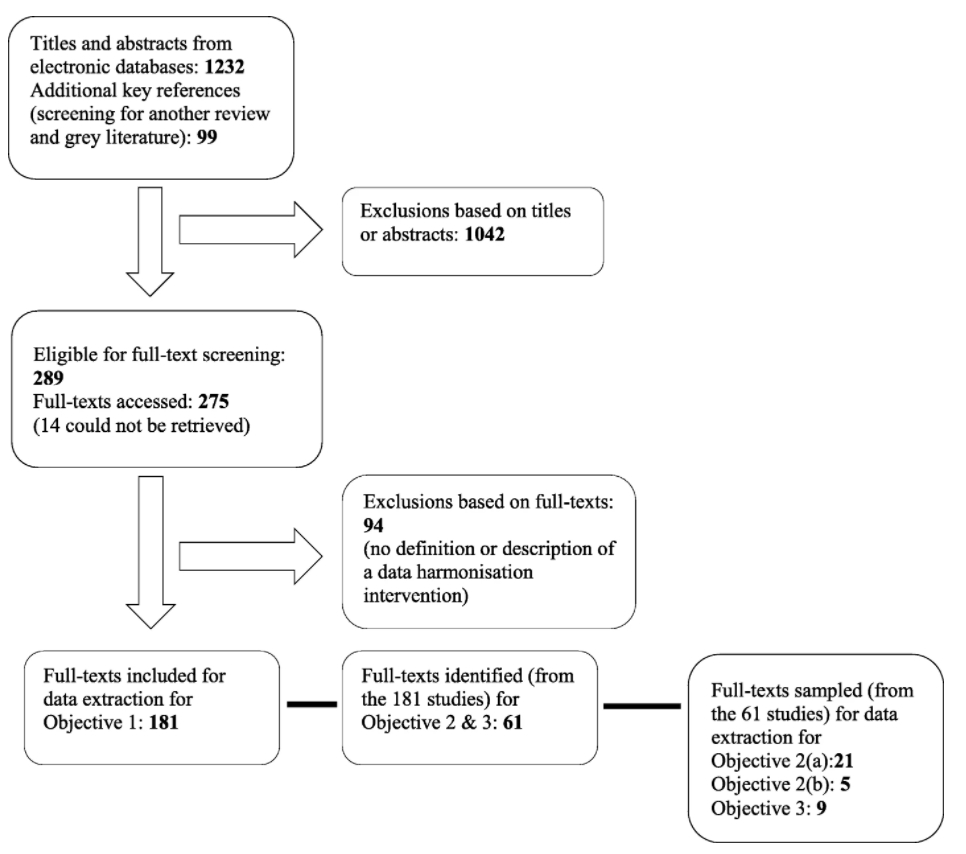
In this 2020 review article published in
BMC Medical Informatics and Decision Making, Schmidt
et al. detail the state of healthcare data harmonization (DH) literature, analyze commonalities among various DH terms, and determine "the causal relationship between DH and health management decision-making." Noting the value of organizing and integrating healthcare data in order to strengthen many aspects of how the healthcare system runs, the authors lay out the methodology and results of their scoping review of the topic. The group had three primary objectives: identifying the key components and processes of healthcare DH, synthesizing the various related definitions of DH, and documenting relationships between DH interventions and healthcare management decision-making. They conclude that "health information exchange" is the most commonly used term among seven key terms, and that there are nine vital characteristics to making DH work well. They also add that DH, when conducted well, positively contributes to clinic, operational, and population surveillance decision-making in healthcare settings.
Posted on October 27, 2020
By LabLynx
Journal articles
Cybersecurity and how it's handled by an organization has many facets, from examining existing systems, setting organizational goals, and investing in training, to probing for weaknesses, monitoring access, and containing breaches. An additional and vital element an organization must consider is how to conduct "effective and interoperable cybersecurity information sharing." As Rantos
et al. note, while the adoption of standards, best practices, and policies prove useful to incorporating shared cybersecurity threat information, "a holistic approach to the interoperability problem" of sharing cyber threat information and intelligence (CTII) is required. The authors lay out their case for this approach in their 2020 paper published in
Computers, concluding that their method effectively "addresses all those factors that can affect the exchange of cybersecurity information among stakeholders."
Posted on October 19, 2020
By LabLynx
Journal articles
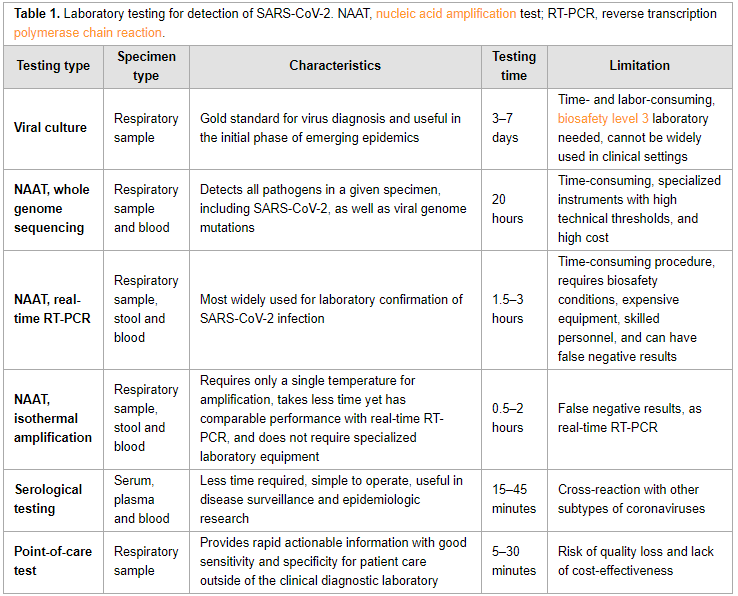
In this "short communication" from the
International Journal of Infectious Diseases, Xu
et al. provide a succinct review of the currently available laboratory testing technologies used to verify COVID-19 infection in patients. The authors review viral cultures, whole genome sequencing, real-time RT-PCR, isothermal amplification, and serological testing, as well as point-of-care testing utilizing one of those methods. They also discuss the sample types that should be collected, and at what stage they are most effective. They close by noting that choosing "a diagnostic assay for COVID-19 should take the characteristics and advantages of various technologies, as well as different clinical scenarios and requirements, into full consideration."
Posted on October 12, 2020
By LabLynx
Journal articles
The quality of data used in not only research centers but also clinical and environmental testing laboratories of all kinds is of great import. For experimental researchers, it means a higher likelihood of reproducible results by others. For testing labs, it means greater assurances of accuracy and outcomes. However, ensuring quality data is more than simply implementing a few good data practices. Stefano Canali, a researcher at Leibniz University Hannover, argues that more must be done, including changing how we conceptualize what "high-quality data" actually entails. In Canali's 2020 essay, published in the journal
Data, a context-based approach to understanding data quality is argued as necessary, "whereby quality should be seen as a result of the context where a dataset is used, and not only of the intrinsic features of the data." After reviewing three philosophical areas of research into data quality, Canali lays out his plan for a more contextual approach of data quality and discusses three practical cases that demonstrate the value of such an approach. He concludes that despite the value of older approaches in some cases, "discussions of quality should also take into account specific contexts and be flexible in connection to these contexts, as opposed to setting up categorizations and hierarchies that are intended be applied to all and any contexts of research practices."
Posted on October 6, 2020
By LabLynx
Journal articles
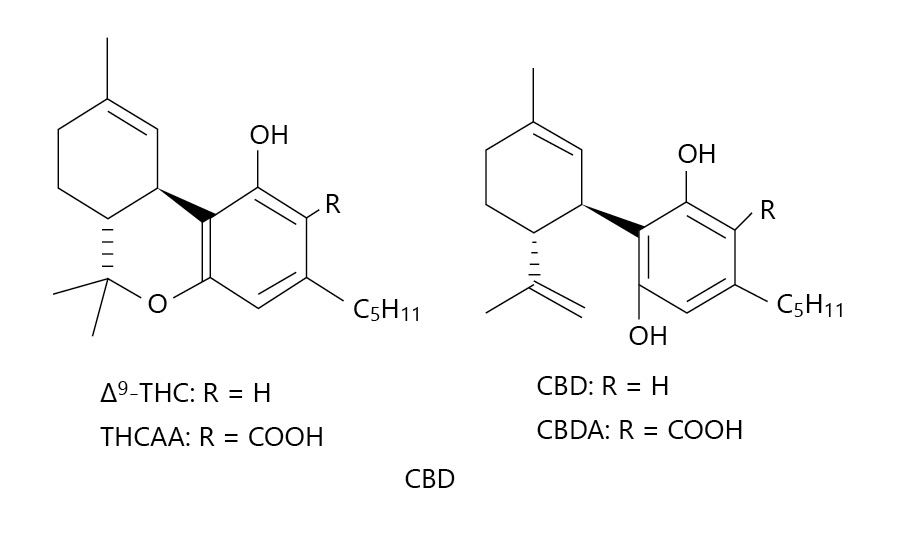
In this 2020 paper published in
Medical Cannabis and Cannabinoids, ElSohly
et al. present the results from an effort to demonstrate the use of a relatively basic gas chromatography–mass spectrometry (GC-MS) method for accurately measuring the cannabidiol, tetrahydrocannabinol, cannabidiolic acid, and tetrahydrocannabinol acid content of CBD oil and hemp oil products. Noting the problems with inaccurate labels and the proliferation of CBD products suddenly for sale, the authors emphasize the importance of a precise and reproducible method for ensuring those products' cannabinoid and acid precursor concentration claims are accurate. From their results, they conclude their validated method achieves that goal.
Posted on October 1, 2020
By LabLynx
Journal articles
A growing trend in producing academic research is abiding by the FAIR principles, which state that produced research data be findable, accessible, interoperable, and re-usable. These, in theory, lend to the important concept of reproducibility. However, what about the software used to generate the data? Often that software is a home-grown solution, and the software and its developers are rarely cited in academic research. This does not lend to reproducibility. As such, researchers such as Davenport
et al. have written on the topic of improving research output reproducibility by addressing good software development and citation practices. In their 2020 paper published in
Data Science Journal, they present a brief essay on the topic, offering background and suggestions to researchers on how to improve research software development, use, and citation. They conclude that "[e]ncouraging the use of modern methods and professional training will improve the quality of research software" and by extension the reproducibility of research results themselves.
Posted on September 21, 2020
By LabLynx
Journal articles
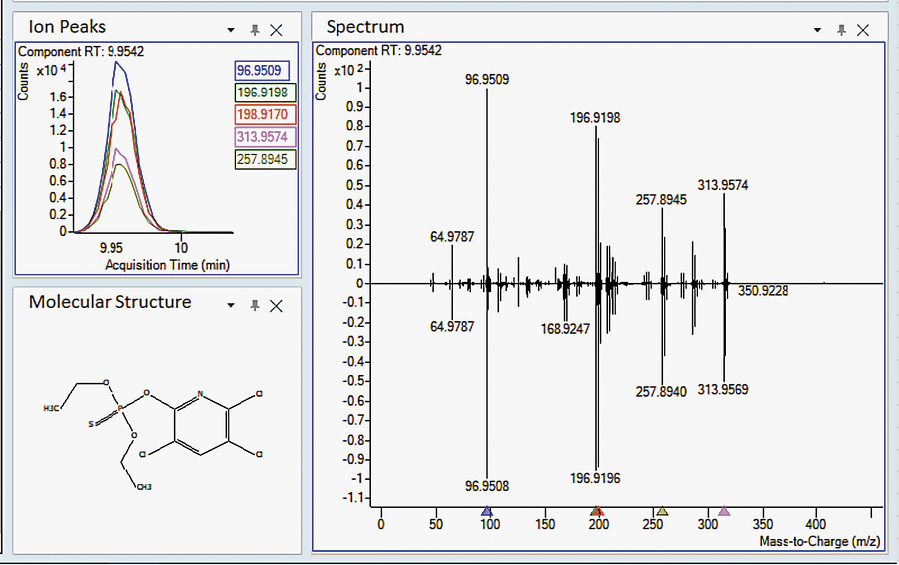
Sure, there are laboratory methods for looking for a small number of specific contaminates in cannabis substrates (target screening), but what about more than a thousand at one time (suspect screening)? In this 2020 paper published in
Medical Cannabis and Cannabinoids, Wylie
et al. demonstrate a method to screen cannabis extracts for more than 1,000 pesticides, herbicides, fungicides, and other pollutants using gas chromatography paired with a high-resolution accurate mass quadrupole time-of-flight mass spectrometer (GC/Q-TOF), in conjunction with several databases. They note that while some governmental bodies are mandating a specific subset of contaminates to be tested for in cannabis products, some cultivators may still use unapproved pesticides and such that aren't officially tested for, putting medical cannabis and recreational users alike at risk. As proof-of-concept, the authors describe their suspect screening materials, methods, and results of using ever-improving mass spectrometry methods to find hundreds of pollutants at one time. Rather than make specific statements about this method, the authors instead let the results of testing confiscated cannabis samples largely speak to the viability of the method.
Posted on September 16, 2020
By LabLynx
Journal articles
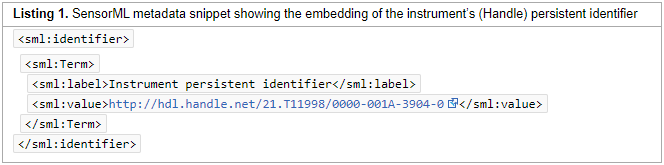
In this 2020 paper published in
Data Science Journal, Stocker et al. present their initial attempts at generating a schema for persistently identifying scientific measuring instruments, much in the same way journal articles and data sets can be persistently identified using digital object identifiers (DOIs). They argue that "a persistent identifier for instruments would enable research data to be persistently associated with" vital metadata associated with instruments used to produce research data, "helping to set data into context." As such, they demonstrate the development and implementation of a schema to address the managements of instruments and the data they produce. After discussing their methodology, results, those results' interpretation, and adopted uses of the schema, the authors conclude by declaring the "practical viability" of the schema "for citation, cross-linking, and retrieval purposes," and promoting the schema's future development and adoption as a necessary task,
Posted on September 15, 2020
By LabLynx
Journal articles
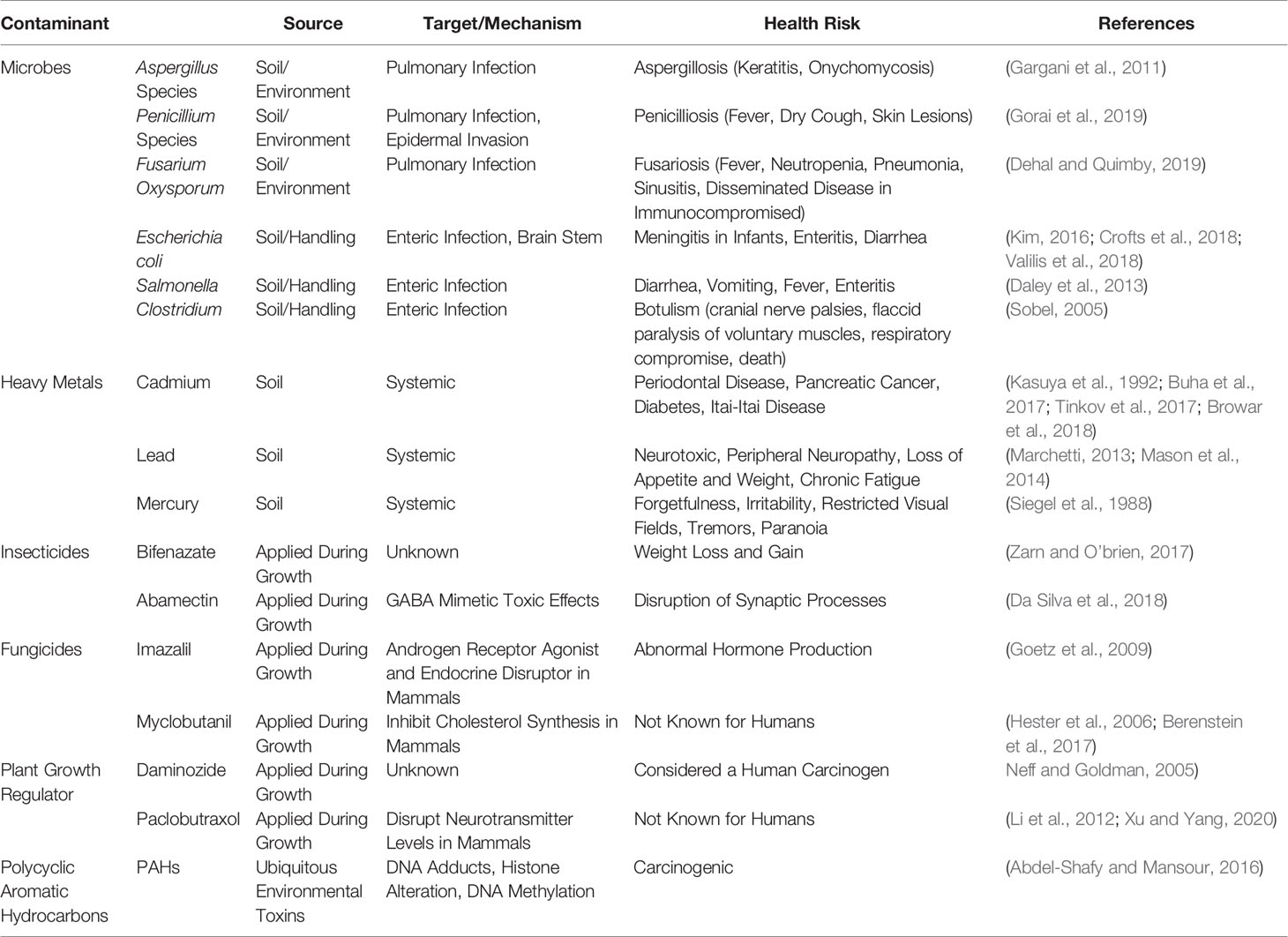
In this 2020 review published in the journal
Frontiers in Pharmacology, Montoya
et al. discuss the various potential contaminants found in cannabis products and how those contaminants may create negative consequences medically, particularly for immunocompromised individuals. Though the authors take a largely global perspective on the topic, they note at several points the lack of consistent standards—particularly in the United States—and what that means for the long-term health of cannabis users, especially as legalization efforts continue to move forward. In addition to contaminants such as microbes, heavy metals, pesticides, plant growth regulators, and polycyclic aromatic hydrocarbons, the authors also address the dangers that come with inaccurate laboratory analyses and labeling of cannabinoid content in cannabidiol (CBD)-based products. They conclude that "it is imperative to develop universal standards for cultivation and testing of products to protect those who consume cannabis."
Posted on September 13, 2020
By LabLynx
Journal articles
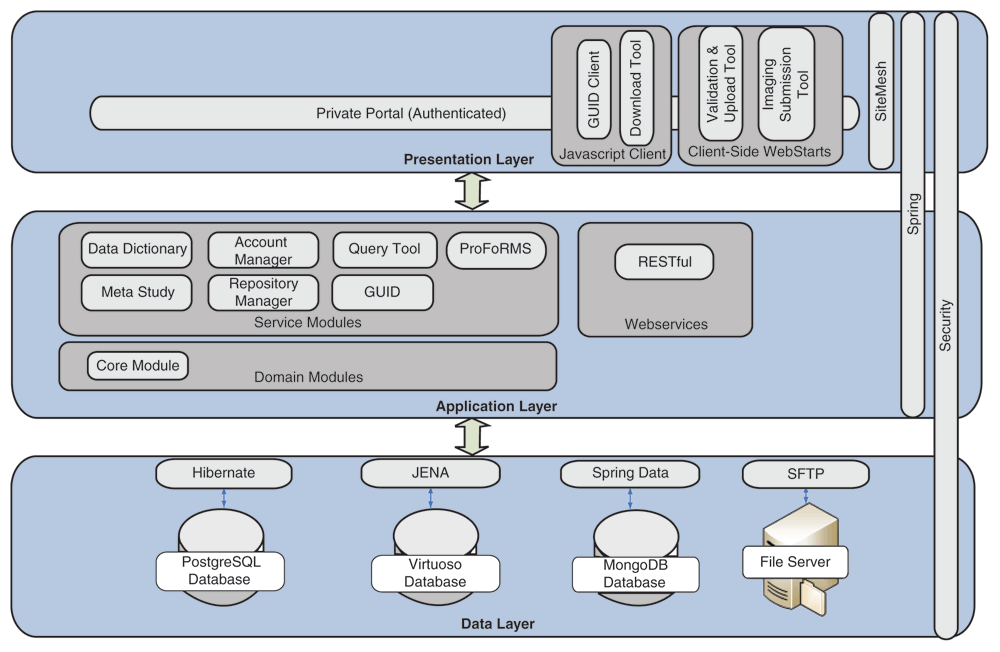
Appearing originally in a 2019 issue of
F1000Research, this recently revised second version sees Navale
et al. expand on their development, implementation, and various uses of the Biomedical Research Informatics Computing System (BRICS), "designed to address the wide-ranging needs of several biomedical research programs" in the U.S. With a focus on using common data elements (CDEs) for improving data quality, consistency, and reuse, the authors explain their approach to BRICS development, how it accepts and processes data, and how users can effectively access and share data for improved translational research. The authors also provide examples of how the open-source BRICS software is being used by the National Institutes of Health and other organizations. They conclude that not only does BRICS further biomedical digital data stewardship under the FAIR principles, but it also "results in sustainable digital biomedical repositories that ensure higher data quality."
Posted on September 2, 2020
By LabLynx
Journal articles
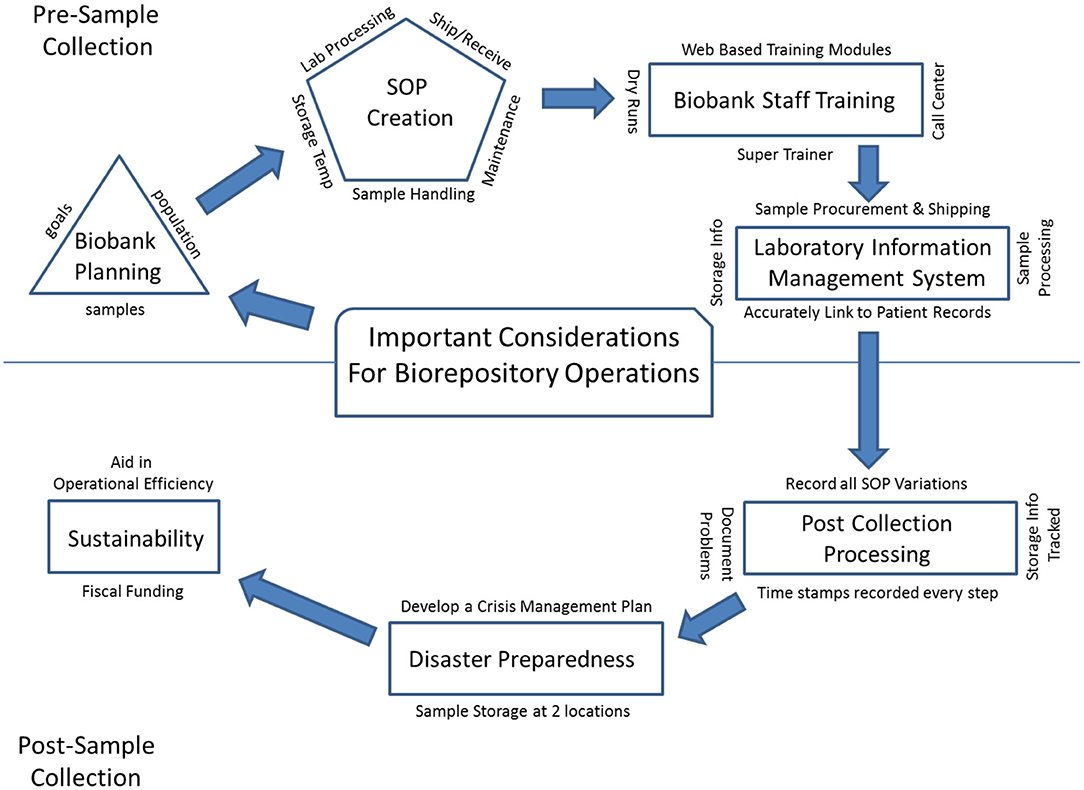
In this 2020 article published in
Frontiers in Public Health, Cicek and Olson of Mayo Clinic discuss the importance of biorepository operations and their focus on the storage and management of biospecimens. In particular, they address the importance of maintaining quality biospecimens and enacting processes and procedures that fulfill the long-term goals of biobanking institutions. After a brief introduction of biobanks and their relation to translational research, the authors discuss the various aspects that go into long-term planning for a successful biobank, including the development of standard operating procedures and staff training programs, as well as the implementation of informatics tools such as the laboratory information management system (LIMS). They conclude by emphasizing that "[b]iorepository operations require an enormous amount of support, from lab and storage space, information technology expertise, and a LIMS to logistics for biospecimen tracking, quality management systems, and appropriate facilities" in order to be most effective in their goals.
Posted on August 25, 2020
By LabLynx
Journal articles
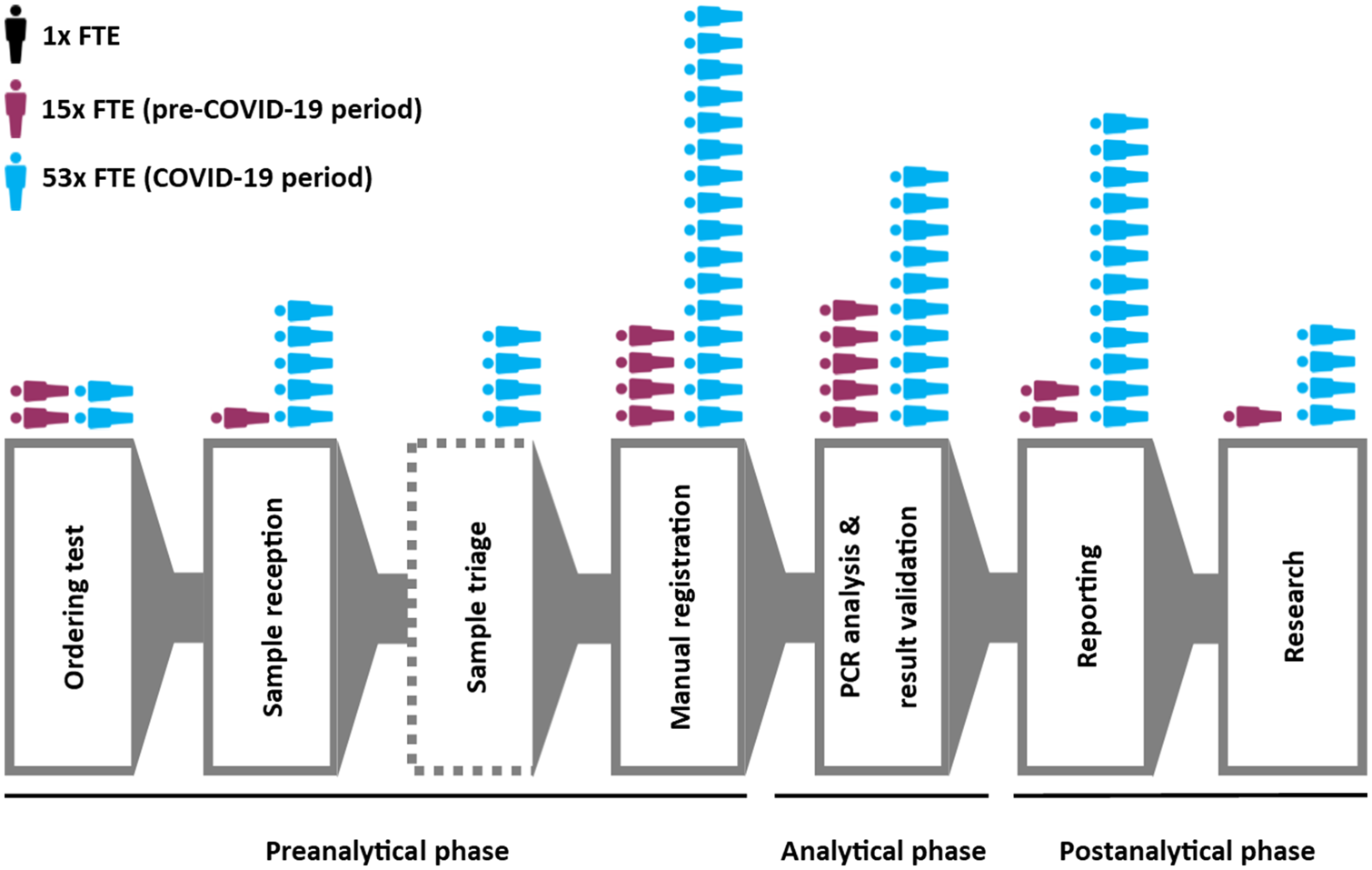
Though the COVID-19 pandemic has been in force for months, seemingly little has been published (even ahead of print) in academic journals of the technological challenges of managing the growing mountain of research and clinical diagnostic data. Weemaes
et al. are one of the exceptions, with this pre-print June publication in the
Journal of the American Medical Informatics Association. The authors, from Belgium's University Hospitals Leuven, present their approach to rapidly expanding their laboratory's laboratory information system (LIS) to address the sudden workflow bottlenecks associated with COVID-19 testing. They describe how using a change management framework to rapidly drive them forward, the authors were able "to streamline sample ordering through a CPOE system, and streamline reporting by developing a database with contact details of all laboratories in Belgium," while improving epidemiological reporting and exploratory data mining of the data for scientific research. They also address the element of "meaningful use" of their LIS, which often gets overlooked.
Posted on August 18, 2020
By LabLynx
Journal articles
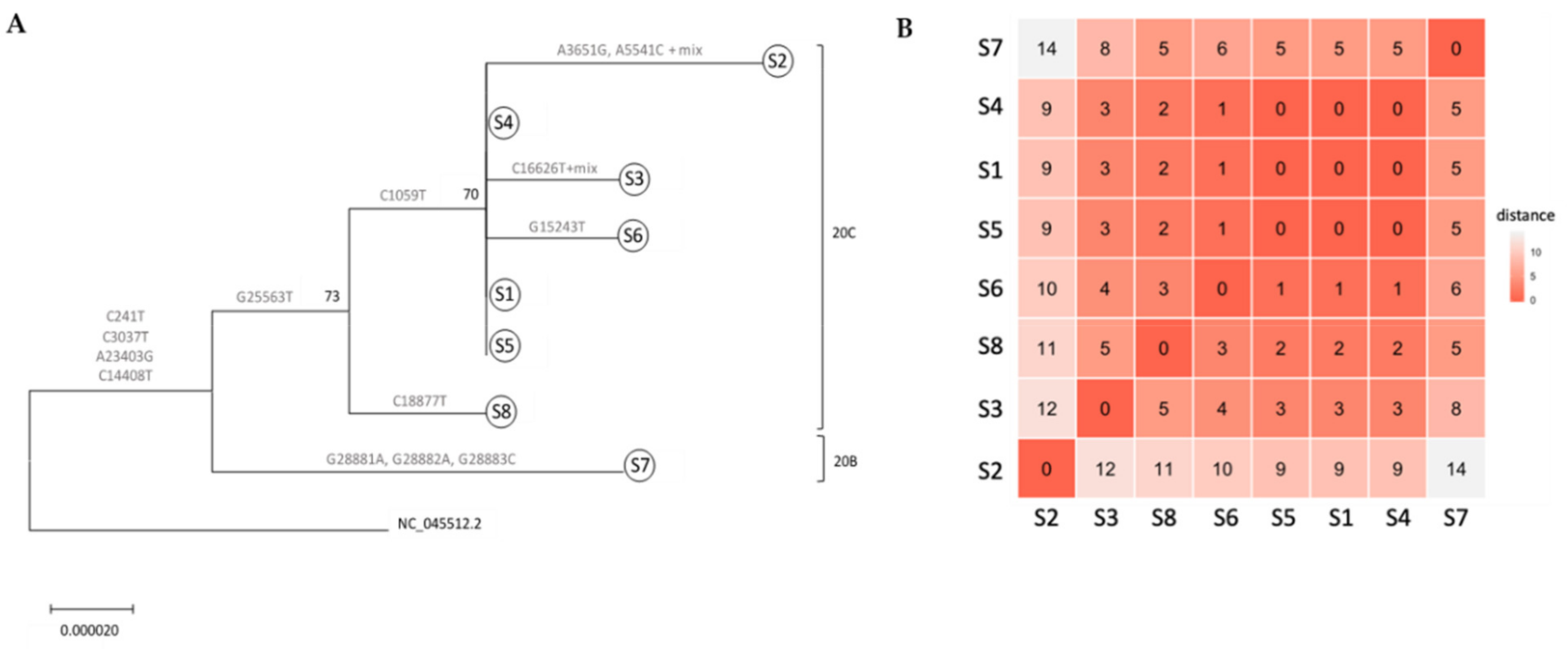
With COVID-19, we think of small outbreaks occurring from humans being in close proximity at restaurants, parties, and other events. But what about laboratories? Zuckerman
et al. share their tale of a small COVID-19 outbreak at Israel’s Central Virology Laboratory (ICVL) in mid-March 2020 and how they used their lab tech to determine the transmission sources. With eight known individuals testing positive for the SARS-CoV-2 virus overall, the researchers walk step by step through their quarantine and testing processes to "elucidate person-to-person transmission events, map individual and common mutations, and examine suspicions regarding contaminated surfaces." Their analyses found person-to-person contact—not contaminated surface contact—was the transmission path. They conclude that their overall analysis verifies the value of molecular testing and capturing complete viral genomes towards determining transmission vectors "and confirms that the strict safety regulations observed in ICVL most likely prevented further spread of the virus."






